Posted by BrendanLong 9/3/2025
Hyperthreading (SMT) and Turbo (clock scaling) are only a part of the variables causing non-linearity, there are a number of other resources that are shared across cores and "run out" as load increases, like memory bandwidth, interconnect capacity, processor caches. Some bottlenecks might come even from the software, like spinlocks, which have non-linear impact on utilization.
Furthermore, most CPU utilization metrics average over very long windows, from several seconds to a minute, but what really matters for the performance of a latency-sensitive server happens in the time-scale of tens to hundreds of milliseconds, and a multi-second average will not distinguish a bursty behavior from a smooth one. The latter has likely much more capacity to scale up.
Unfortunately, the suggested approach is not that accurate either, because it hinges on two inherently unstable concepts
> Benchmark how much work your server can do before having errors or unacceptable latency.
The measurement of this is extremely noisy, as you want to detect the point where the server starts becoming unstable. Even if you look at a very simple queueing theory model, the derivatives close to saturation explode, so any nondeterministic noise is extremely amplified.
> Report how much work your server is currently doing.
There is rarely a stable definition of "work". Is it RPS? Request cost can vary even throughout the day. Is it instructions? Same, the typical IPC can vary.
Ultimately, the confidence intervals you get from the load testing approach might be as large as what you can get from building an empirical model from utilization measurement, as long as you measure your utilization correctly.
What most people care about is some combination of latency and utilization. As a very rough rule of thumb, for many workloads you can get up to about 80% CPU utilization before you start seeing serious impacts on workload latency. Beyond that you can increase utilization but you start seeing your workload latency suffer from all of the effects you mentioned.
To know how much latency is impacted by utilization you need to measure your specific workload. Also, how much you care about latency depends on what you're doing. In many cases people care much more about throughput than latency, so if that's the top metric then optimize for that. If you care about application latency as well as throughput then you need to measure both of those and decide what tradeoffs are acceptable.
I think this is probably one of the most important points... similarly, is this public facing work dealing with any kind of user request, or is it simply crunching numbers/data to build an AI model from a stable backlog/queue?
My take has always been with modern multi-core, hyper-threaded CPUs that are burstable is to consider ~60% a "loaded" server. That should have work split if it's that way for any significant portion of a day. Mostly dealing with user-facing services. So bursts and higher traffic portions of the day are dramatically different from lower utilization portions of the day.
A decade ago, this lead to a lot of work for cloud provisioning on demand for the heavier load times. Today it's a bit more complicated when you have servers with 100+ cores as an option for under $30k (guestimate based on $10k CPU price). Today, I'd lean to over-provisioning dedicated server hardware and supplement with cloud services (and/or self-cloud-like on K8s) as pragmatically as reasonable... depending on the services of course. I'm not currently in a position where I have this level of input though.
Just looking at how, as an example, StackOverflow scaled in the early days is even more possible/prudent today to a much larger extent... You can go a very long way with a half/full rack and a 10gb uplink in a colo data center or two.
In any case, for me... >= 65% CPU load for >= 30m/day means it's at 100% effective utilization, and needs expansion relatively soon. Just my own take.
I think this depends on workload still because IO heavy apps hyperthread well and can push up to 100%. I think most of the apps I've worked on end up being IO bound because "waiting on SQL results" or the more generic "waiting on downstream results" is 90% of their runtime. They might spend more time reading those responses off the wire than they do actually processing anything.
There are definitely things that isn't true of though, and your metrics read about right to me.
If one can buy used, then previous generation 128C 256T epyc server is less than $5k. For homelabs that can accept non-rackmount gear it's less than $3k.
The lie is the assumption that CPU time is linear in useful work, but that has nothing to do with the definition of utilization, it's just something that people sometimes naively believe.
> CPU utilization isn't a lie, % CPU utilization is
What do you mean by this? Utilization is, by definition, a ratio. % just determines that the scale is in [0, 100].
- operations are implemented in different sub-units of each core
- operations are pipelined, to help saturate these sub-units, so multiple ops executing on different sub-units can be in-flight at the same time
- operations are reordered and their execution is predicted, to help saturate the pipelines
Given all of these, to report the overall saturation of each core sounds like quite the challenge. It'd mean collecting data on how busy each sub-unit is, versus how busy it could be, then weighing that against how saturated the pipelines are leading there. Maybe one sub-unit is being fed to its brink, but another could still be fed work, it just isn't: maybe the program cannot do so, or isn't willing to do so, doesn't matter.
And so none of this would show up on the scheduler I believe. From the scheduler data, you get the assignment saturation, and then whatever the CPU ended up executing is whatever it did. Did it only do integer math? Did it only do matrix math? Busy spin? Something else? Maybe most sub-units remained completely dark. It's not a utilization ratio then though, but an assignment ratio. How much time each logical core spent assigned work, versus how much it didn't.
Provided I'm not off-base, I really don't find this to be a matter of "naivity" then on people's part. It's an honestly incorrect use of language. Regardless of the reason, e.g. if the kernel cannot actually determine the kind of utilization I describe, or if it doesn't make sense on a fundamental level somehow to try to, this still doesn't justify torturing the language by calling this utilization. It could be just referred to what it is then: assignment. This is like the difference between reserved and committed memory. Or like the difference between me working from 9-5, and me being on meetings from 9-1 and working from 1-5.
So in Linux (and I assume elsewhere) there were attempts to figure out if the cost in time/power to move up to a higher power state would be worth the faster processing, or if staying lower power but slower would end up using less power because it was a short task.
I think the last chips I remember seeing numbers for were some of the older Apple M-series chips, and they were lightning fast to switch power levels. That would certainly make it easier to figure out if it was worth going up to a higher power state, if I’m remembering correctly.
Also swapping the governor was trivial and reliable. Modifying fan profiles has always been a bit of a struggle for me, with huge differences in hardware support, persistence etc.
jumping into action when browsing
This is why I sigh really hard when people talk about some measurement of FLOPS per second, as if it's the only thing that matters.
It matters. Perhaps it matters a lot for specific workloads. But most general workloads are integer-based.
The %CPU suggestions ran contrary to (and were much more conservative than) the "old wisdom" that would otherwise have been used. It worked out great at much lower cost than otherwise.
What I'm trying to say is you shouldn't be afraid of using semi-crappy indicators just because they're semi-crappy. If it's the best you got it might be good enough anyway.
In the case of CPU utilisation, though, the number in production shouldn't go above 40 % for many reasons. At 40 % there's usually still a little headroom. The mistake of the author was not using fundamentals of queueing theory to avoid high utilisation!
Agree. Another example of this is for metrics as percentiles per host that you have to average, vs histograms per host that get percentile calculated at aggregation time among hosts. Sure an avg/max of a percentile is technically not a percentile, but in practice switching between one or the other hasn’t affected my operations at all. Yet I know some people are adamant about mathematical correctness as if that translates to operations.
It's not good to go much over 50% on a server (assuming half the cpus are just hyperthreads), because you're essentially relying on your load being able to share the actual cpu cores. At some point, when the load increases too much, there may not be any headroom left for sharing those physical cpus. You then get to the point where adding a little bit more load to 80% suddenly results in 95% utilization.
The important part is of course to ask yourself the question "how much increased load may I need to handle, and how much can I degrade system performance in doing so?" You may work in an industry that only ever sees 10 % additional load at timescales where scaling is unfeasible, and then you can pick a significantly higher normal utilisation level. Or maybe you're in an industry where you cannot degrade performance by more than 10 % even if hit by five times the load – then you need a much, much more conservative target for utilisation.
[0]: https://www.brendangregg.com/blog/2017-05-09/cpu-utilization...
It should be possible from the information you can get on a CPU from the OS to better estimate utilisation involving at the very least these two factors. It becomes a bit more tricky to start to account for significantly going past the cache or available memory bandwidth and the potential drop in performance to existing threads that occurs from the increased pipeline stalls. But it can definitely be done better than it is currently.
IBM's Power cpu's have also traditionally done a great job with SMT compared to Intel's implementation.
But overall yeah.
Going from 1 thread to 2 threads doubled the speed as expected. Going from 2 to 4 doubled it again. Going from 4 to 8 was only ~15% faster.
I imagine you could probably create a contrived benchmark that actually gives you nearly double the performance from SMT, but I don't know what it would look like. Maybe some benchmark that is written to deliberately constantly miss cache?
Side note, I should run that POV-Ray test again. It's been years since I've even use POV-Ray.
2 chefs with one stove. As long as they're doing other things than frying it's ok and speeding things up but once they both need the stove you're down to 1 working and 1 waiting.
Especially when it come to those advertisements “6 large rolls == 18 normal rolls”.
Sure it might be thicker but nobody wipes their butt with 1/3 a square…
as in youd only use it to wipe excrement from around your sphincter
The difference between two threads and one core or two cores with shared resources?
Nothing is really all that neat and clean.
It more of a 2 level NUMA type architecture with 2 sets of 6 SMP sets of 2.
The scheduler may look at it that way (depending), but to the end user? Or even to most of the system? Nah.
Instead of having a big core with two instruction pipelines sharing big ALUs etc, they have two (or more) cores that combine resources and become one core.
Almost the same, yet quite different.
Anyway, by my reading, it’s also similar to the Itanic, er, Itanium, where the “cores” that got combined were pipeline stages.
I didn't expect an article on this style. I was expecting the normal Linux/Windows utilization but wtf it's all RAM bottlenecked and the CPU is actually quiet and possibly down clocking thing.
CPU Utilization is only how many cores are given threads to run by the OS (be it Windows or Linux). Those threads could be 100% blocked on memcpy but that's still CPU utilization.
-------
Hyperthreads help: if one thread is truly CPU bound (or even more specifically: AVX / Vector unit bound), while a 2nd thread is hyperthreaded together that's memcpy / RAM bound, you'll magically get more performance due to higher utilization of resources. (Load/store units are separate from AVX compute units).
In any case, this is a perennial subject with always new discoveries about how CPU Utilization is far less intuitive than many think. Still kinda fun to learn about new perspectives on this matter in any case.
There are many reasons for the lack of a proportional relationship, even in the case where you do not have hyperthreading or downclocking (in which cases you just need to interpret %CPU utilisation in that context, rather than declare it "a lie"). Even in apple silicon where these are usually not an issue, you often do not get an exactly proportional scaling. There may be overheads when utilising multiple cores wrt how data is passed around, or resource bottlenecks other than CPU.
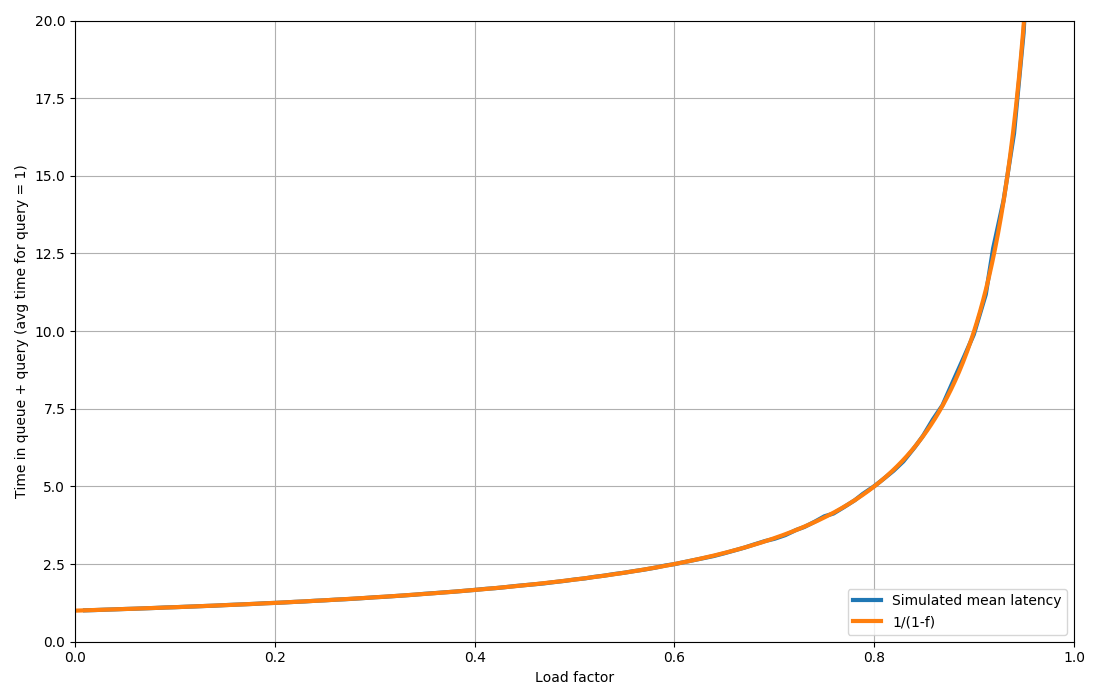
Up to a hair over 60% utilization the queuing delays on any work queue remain essentially negligible. At 70 they become noticeable, and at 80% they've doubled. And then it just turns into a shitshow from there on.
The rule of thumb is 60% is zero, and 80% is the inflection point where delays go exponential.
The biggest cluster I ran, we hit about 65% CPU at our target P95 time, which is pretty much right on the theoretical mark.
The biggest problem was not variance in request rate it was variance in request cost, which is usually where queuing kicks in, unless you're being dumb about things. I think for a lot of apps p98 is probably a better metric to chase, p99 and p100 are useful for understanding your application better, but I'm not sure you want your bosses to fixate on them.
But our contracts were for p95, which was fortunate given the workload, or at least whoever made the contracts got good advice from the engineering team.
I really should have a favorite couple of links or books but unfortunately I do not. I will put that on my todo list.
The magic search terms are “queue size/length”, “utilization”.
One way to get closer to reliable performance is to apply cpu scheduler limits to what runs your applications to keep them below a given threshold. This way you can better ensure you can sustain a given amount of performance. You don't want to run at 100% cpu for long, especially if disk i/o becomes hampered, system load skyrockets, and availability starts to plummet. Two thousand servers with 5000ms ping times due to system load is not a fun day at the office.
(And actually you'll never get a completely accurate view, as performance can change per-server. Rack two identical servers in two different racks, run the same app on each, and you may see different real-world performance. One rack may be hotter than the other, there could be hidden hardware or firmware differences, etc. Even within a server, if one CPU is just nearer a hotter component than on another server, for reasons)
- Pinned to 6 cores: 28k QPS
- Pinned to 12 cores: 56k QPS
- All 24 cores: 62k QPS
I'm not sure how this applies to realistic workloads where you're using all of the cores but not maxing them out, but it looks like hyperthreading only adds ~10% performance in this case.
At 51% reported CPU utilization, it's doing about 80% of the maximum requests per second, and it can't get above 80% utilization.
I also added a section: https://www.brendanlong.com/cpu-utilization-is-a-lie.html#bo...
{kind=link}