> Before your agent can do anything useful, it needs to know what tools are available. MCP’s answer is to dump the entire tool catalog into the conversation as JSON Schema. Every tool, every parameter, every option.
Because this simply isn't true anymore for the best clients, like Claude Code.
Similar to how Skills were designed[1] to be searchable without dumping everything into context, MCP tools can (and does in Claude Code) work the same way.
See https://www.anthropic.com/engineering/advanced-tool-use and https://x.com/trq212/status/2011523109871108570 and https://platform.claude.com/docs/en/agents-and-tools/tool-us...
[1] https://agentskills.io/specification#progressive-disclosure
Regardless, most MCPs are dumping. I know Cloudflare MCP is amazing but other 1000 useful MCPs are not.
First, MCP tools are sent on every request. If you look at the notion MCP the search tool description is basically a mini tutorial. This is going right into the context window. Given that in most cases MCP tool loading is all or nothing (unless you pre-select the tools by some other means) MCP in general will bloat your context significantly. I think I counted about 20 tools in GitHub Copilot VSCode extension recently. That's a lot!
Second, MCP tools are not compossible. When I call the notion search tool I get a dump of whatever they decide to return which might be a lot. The model has no means to decide how much data to process. You normally get a JSON data dump with many token-unfriendly data-points like identifiers, urls, etc. The CLI-based approach on the other hand is scriptable. Coding assistant will typically pipe the tool in jq or tail to process the data chunk by chunk because this is how they are trained these days.
If you want to use MCP in your agent, you need to bring in the MCP model and all of its baggage which is a lot. You need to handle oauth, handle tool loading and selection, reloading, etc.
The simpler solution is to have a single MCP server handling all of the things at system level and then have a tiny CLI that can call into the tools.
In the case of mcpshim (which I posted in another comment) the CLI communicates with the sever via a very simple unix socket using simple json. In fact, it is so simple that you can create a bash client in 5 lines of code.
This method is practically universal because most AI agents these days know how to use SKILLs. So the goal is to have more CLI tools. But instead of writing CLI for every service you can simply pivot on top of their existing MCP.
This solves the context problem in a very elegant way in my opinion.
Awesome TUIs: https://github.com/rothgar/awesome-tuis
Awesome CLIs: https://github.com/agarrharr/awesome-cli-apps
Terminal Trove: https://terminaltrove.com/
I guess this is another one shows that the CLI and Unix is coming back in 2026.
I've also launched https://mcpshim.dev (https://github.com/mcpshim/mcpshim).
The unix way is the best way.
Compared both
---
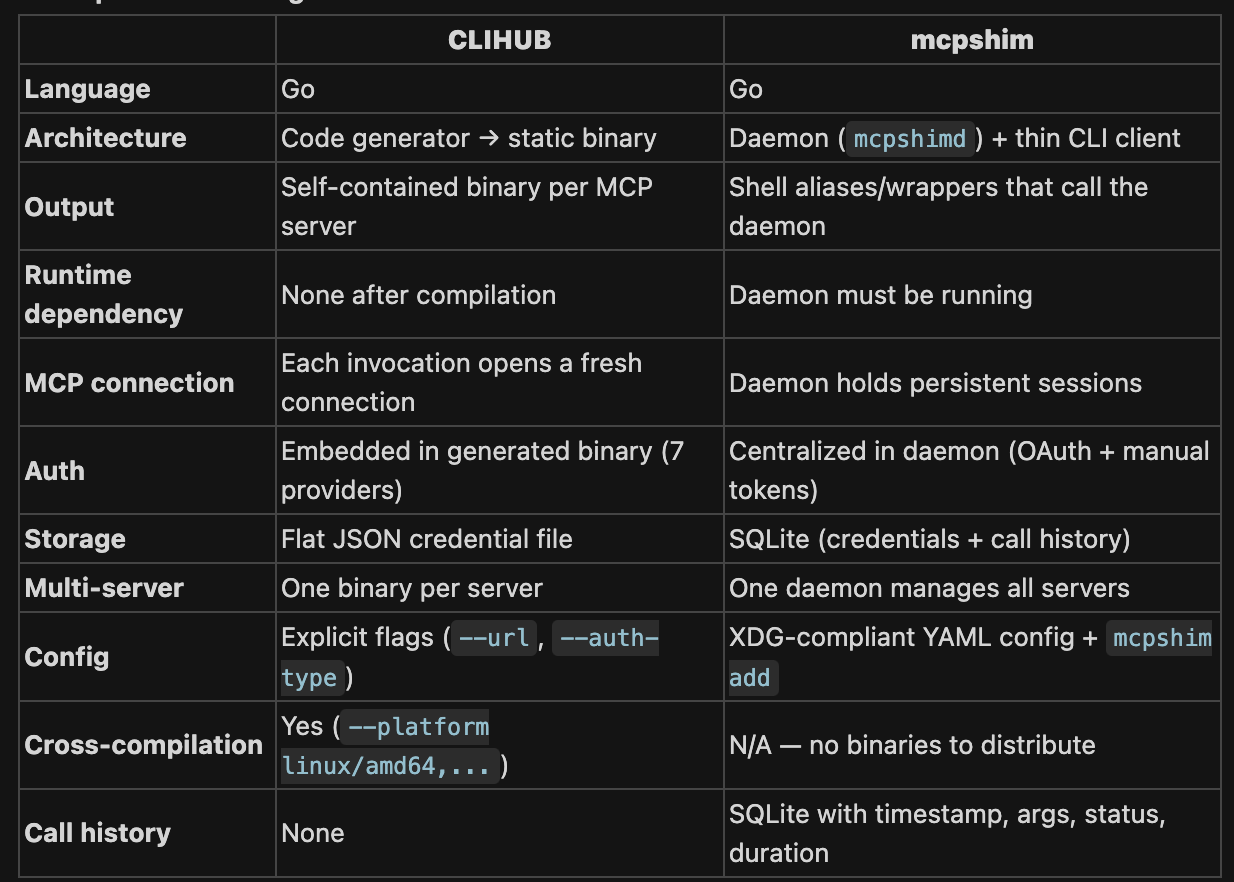
TL;DR CLIHUB compiles MCP servers into portable, self-contained binaries — think of it like a compiler. Best for distribution, CI, and environments where you can't run a daemon.
mcpshim is a runtime bridge — think of it like a local proxy. Best for developers juggling many MCP servers locally, especially when paired with LLM agents that benefit from persistent connections and lightweight aliases.
---
https://cdn.zappy.app/b908e63a442179801e406b01cf412433.png (table comparison)
---
One important aspect of mcpshim which you might want to bring into clihub is the history idea. Imagine if the model wants to know what it did couple of days ago. It will be nice to have an answer for that if you record the tool calls in a file and then allow the agent to query the file.
My use cases are almost all 3rd party integrations.
Have you seen any improvements converting on MCPs that require persistency into CLI?
But yeah, a concrete example is playwright-mcp vs playwright-cli: https://testcollab.com/blog/playwright-cli
I was actually thinking if I should support daemons just to support playwright. Now I don't have a use case for it
Even the smallest models are RL trained to use shell commands perfectly. Gemini 3 flash performs better with a cli with 20 commands vs 20+ tools in my testing.
cli also works well in terms of maintaining KV cache (changing tools mid say to improve model performance suffers from kv cache vs cli —help command only showing manual for specific command in append only fashion)
Writing your tools as unix like cli also has a nice benefit of model being able to pipe multiple commands together. In the case of browser, i wrote mini-browser which frontier models use much better than explicit tools to control browser because they can compose a giant command sequence to one shot task.
ALSO... the permission boundary is clearer. You can whitelist commands, flags, working dir... it becomes manageable.
HOWEVER... packaging still matters. A “small” CLI that pulls in a giant runtime kills the benefit.
I want the discipline of small protocol plus big cache. Cheap models can summarize what they did and avoid full context in every step...
LLM only know `linear` tool exists.
I ask "get me the comments in the last issue"
Next call LLM does is
`linear --help 2>&1 | grep -i -E "search|list.issue|get.issue")` then `linear list-issues --raw '{"limit": 3}' -o json 2>&1 | head -80)` then `linear list-comments --issue-id "abc1ceae-aaaa-bbbb-9aaa-6bef0325ebd0" 2>&1)`
So even the --help has filtering by default. Current models are pretty good
CLIHub
- written in go
- zero-dependency binaries
- cross-compilation built-in (works on all platforms)
- supports OAuth2 w/ PKCE, S2S, Google SA, API key, basic, bearer. Can be extended further
MCPorter
- TS
- huge dependency list
- runtime dependency on bun
- Auth supports OAuth + basic token
- Has many features like SDK, daemons (for certain MCPs), auto config discovery etc.
MCPorter is more complete tbh. Has many nice to have features for advanced use cases.
My use case is simple. Does it generate a CLI that works? Mainly oauth is the blocker since that logic needs to be custom implemented to the CLI.
{kind=link}