Posted by TORcicada 1 day ago
Are you perhaps confusing Groq with the Etched approach? IIUC Etched is the company that "burned the transformer onto a chip". Groq uses LPUs that are more generalist (they can run many transformers and some other architectures) and their speed comes from using SRAM.
I think a better question would be "when are FPGAs going to stop being so ridiculously overpriced". That feels more possible to me (but still unlikely).
5 years ago we would've called it a Machine Learning algorithm. 5 years before that, a Big Data algorithm.
> 5 years before that, a Big Data algorithm.
The DNN part? Absolutely not.
I don’t know why people feel the need for such revisionism but AI has been a field encompassing things far more basic than this for longer than most commenters have been alive.
When I was 13, having just started programming, I picked up a book from a "junk bin" at a book store on Artificial Intelligence. It must have been from the mid-80s if not older.
It had an entire chapter on syllogism[1] and how to implement a program to spit them out based on user input. As I recall it basically amounted to some string exteaction assuming user followed a template and string concatenation to generate the result. I distinctly recall not being impressed about such a trivial thing being part of a book on AI.
In the 1990s I remember taking my friend's IRC chat history and running it through a Markov model to generate drivel, which was really entertaining.
> The AXOL1TL V5 architecture comprises a VICReg-trained feature extractor stacked on top of a VAE.
Some tried to hold out and keep calling it "ML" or just "neural networks" but eventually their colleagues start asking them why they aren't doing any AI research like the other people they read about. For a while some would say "I just say AI for the grant proposals", but it's hard to avoid buzzwords when you're writing it 3 times a day I guess.
Although note that the paper doesn't say "AI". The buzzword there is "anomaly detection" which is even weirder: somehow in collider physics it's now the preferred word for "autoencoder", even though the experiments have always thrown out 99.998% of their data with "classical" algorithms.
I hacked on it a while back, added Comv2dTranspose support to it.
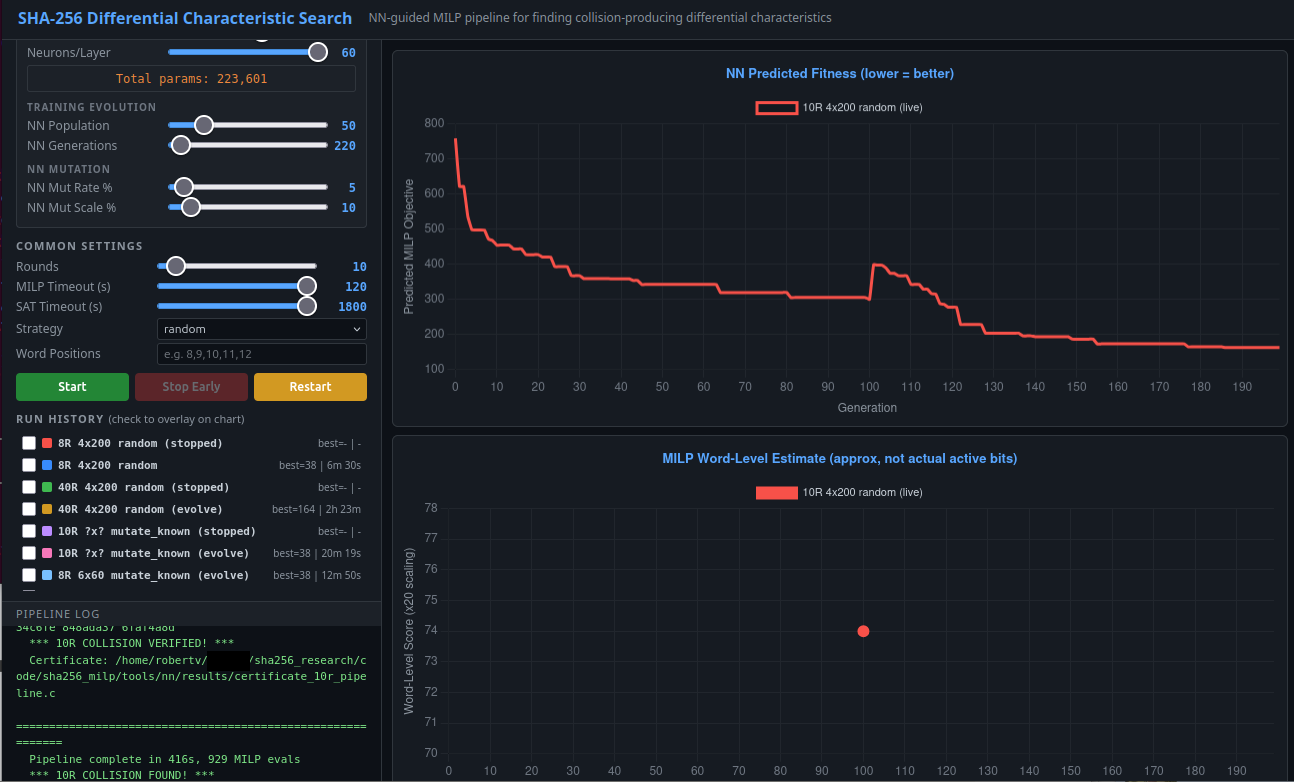
After training it fully, we moved on to the inference stage, trying it on the round counts we didn't have data for! It turned out ... to have zero predictive ability on data it didn't see before. This is on well-structured, sensible extrapolations for what worked at lower round counts, and what could be selected based on real algabraic correlations. This mini neural network isn't part of our pipeline now.
[1] screenshot: https://taonexus.com/publicfiles/mar2026/neural-network.png
{kind=link}