Posted by jeffmcjunkin 9 hours ago
At least, as of this post
We are at least 1 year and at most 2 years until they surpass closed models for everyday tasks that can be done locally to save spending on tokens.
Until they pass what closed models today can do.
By that time, closed models will be 4 years ahead.
Google would not be giving this away if they believed local open models could win.
Google is doing this to slow down Anthropic, OpenAI, and the Chinese, knowing that in the fullness of time they can be the leader. They'll stop being so generous once the dust settles.
Google, at least, is likely interested in such a scenario, given their broad smartphone market. And if their local Gemma/Gemini-nano LLMs perform better with Gemini in the cloud, that would naturally be a significant advantage.
First message:
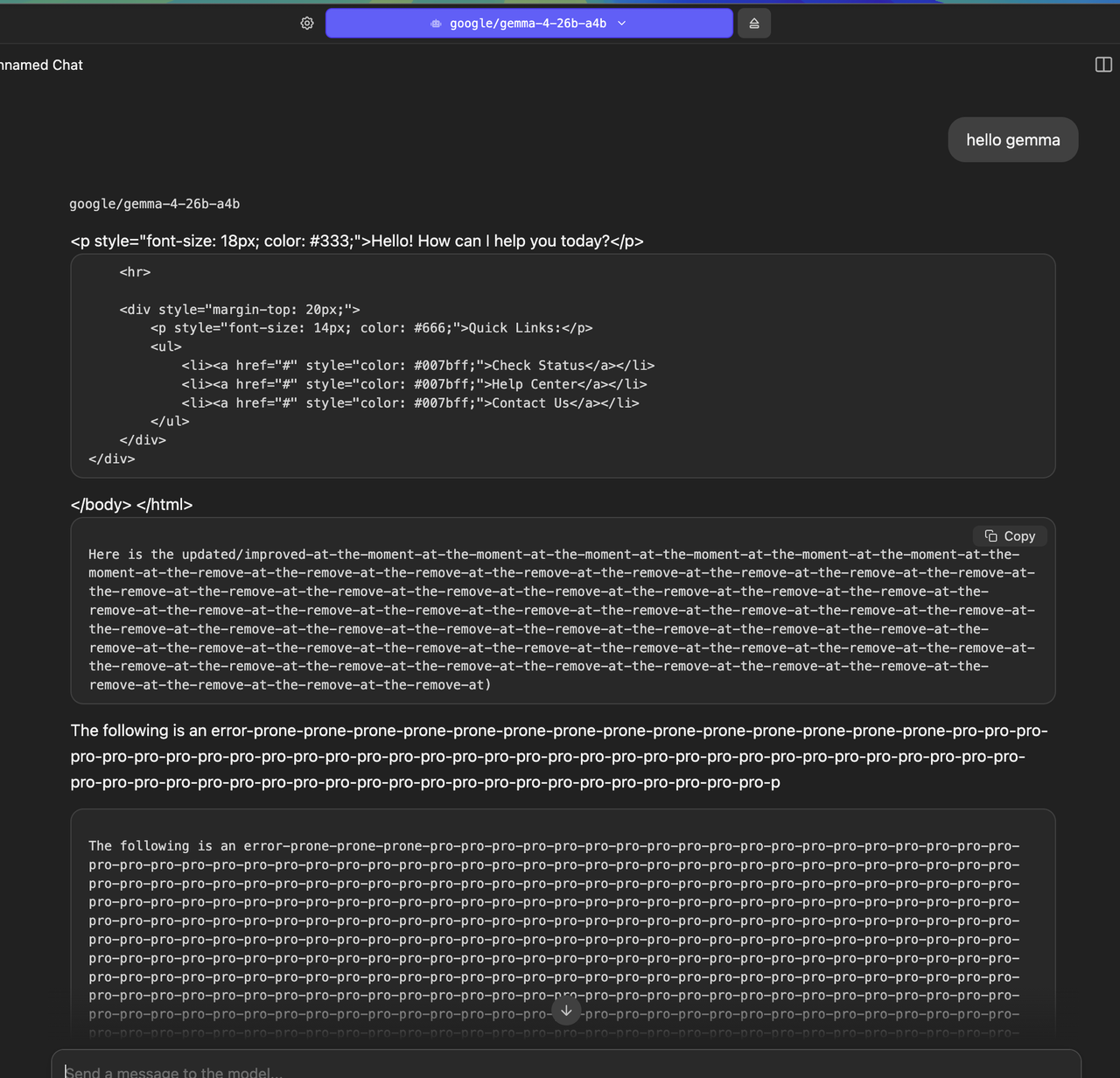
https://i.postimg.cc/yNZzmGMM/Screenshot-2026-04-03-at-12-44...
Not sure if I'm doing something wrong?
This more or less reflects my experience with most local models over the last couple years (although admittedly most aren't anywhere near this bad). People keep saying they're useful and yet I can't get them to be consistently useful at all.
I had a similarly bad experience running Qwen 3.5 35b a3b directly through llama.cpp. It would massively overthink every request. Somehow in OpenCode it just worked.
I think it comes down to temperature and such (see daniel‘s post), but I haven’t messed with it enough to be sure.
Base model (without instruction/chat tuning) just generates text non stop ("autocomplete on steroids") and text is not necessarily even formatted as chat -- most text in training data isn't dialogue, after all.
{kind=link}