Posted by aray07 8 hours ago
To me, it is hard to reject this hypothesis today. The fact that Anthropic is rapidly trying to increase price may betray the fact that their recent lead is at the cost of dramatically higher operating costs. Their gross margins in this past quarter will be an important data point on this.
I think the tendency for graphs of model assessment to display the log of cost/tokens on the x axis (i.e. Artificial Analysis' site) has obscured this dynamic.
(* explained at https://news.ycombinator.com/item?id=26998308)
The power dynamics are also vastly against me. I represent a fraction of my employer's labour, but my employer represents 100% of my income.
That dynamic is totally inverted with AI. You are a rounding error on their revenue sheet, they have a monopoly on your work throughput. How do you budget an workforce that could turn 20% more expensive overnight?
This is why there are a ton of corps running the open source models in house... Known costs, known performance, upgrade as you see fit. The consumer backlash against 4o was noted by a few orgs, and they saw the writing on the wall... they didnt want to develop against a platform built on quicksand (see openweb, apps on Facebook and a host of other examples).
There are people out there making smart AI business decisions, to have control over performance and costs.
If you've got something to share I'd love to see it.
I'd also flip your framing on its head. One of the advantages of human labor over agents is accountability. Someone needs to own the work at the end of the day, and the incentive alignment is stronger for humans given that there is a real cost to being fired.
I think we're reaching the point where more developers need to start right-sizing the model and effort level to the task. It was easy to get comfortable with using the best model at the highest setting for everything for a while, but as the models continue to scale and reasoning token budgets grow, that's no longer a safe default unless you have unlimited budgets.
I welcome the idea of having multiple points on this curve that I can choose from. depending on the task. I'd welcome an option to have an even larger model that I could pull out for complex and important tasks, even if I had to let it run for 60 minutes in the background and made my entire 5-hour token quota disappear in one question.
I know not everyone wants this mental overhead, though. I predict we'll see more attempts at smart routing to different models depending on the task, along with the predictable complaints from everyone when the results are less than predictable.
For a while I used Cerebras Code for 50 USD a month with them running a GLM model and giving you millions of tokens per day. It did a lot of heavy lifting in a software migration I was doing at the time (and made it DOABLE in the first place), BUT there were about 10 different places where the migration got fucked up and had to manually be fixed - files left over after refactoring (what's worse, duplicated ones basically), some constants and routes that are dead code, some development pages that weren't removed when they were superseded by others and so on.
I would say that Claude Code with throwing Opus at most problems (and it using Sonnet or Haiku for sub-agents for simple and well specified tasks) is actually way better, simply because it fucks things up less often and review iterations at least catch when things are going wrong like that. Worse models (and pretty much every one that I can afford to launch locally, even ones that need around ~80 GB of VRAM in the context of an org wanting to self-host stuff) will be confidently wrong and place time bombs in your codebases that you won't even be aware of if you don't pay enough attention to everything - even when the task was rote bullshit that any model worth its salt should have resolved with 0 issues.
My fear is that models that would let me truly be as productive as I want with any degree of confidence might be Mythos tier and the economics of that just wouldn't work out.
For handing work off to an LLM in large chunks, picking the best model available is the only way to go right now.
I’m curious how to even do it. I have no idea how to choose which model to use in advance of a given task, regardless of the mental overhead.
And unless you can predict perfectly what you need, there’s going to be some overuse due to choosing the wrong model and having to redo some work with a better model, I assume?
Even EMs and TPMs are assigning people based on their previous experience, which generally boils down to "i've seen this task before and I know what's involved," "this task is small, and I know what's involved," or "this task is too big and needs to be understood better."
That's how things worked pre-AI, and old problems are new problems again.
When you run any bigger project, you have senior folks who tackle hardest parts of it, experienced folks who can churn out massive amounts of code, junior folks who target smaller/simpler/better scoped problems, etc.
We don't default to tell the most senior engineer "you solve all of those problems". But they're often involved in evaluation/scoping down/breakdown of problem/supervising/correcting/etc.
There's tons of analogies and decades of industry experience to apply here.
I'm not saying that can't be done, but taking a large task that hasn't been broken down needs, you guessed it, a powerful agent. that's your senior engineer who can figure out the rote parts, the medium parts, and the thorny parts.
the goal isn't to have an engineer do that. we should still be throwing powerful agents at a problem, they should just be delegating the work more efficiently.
throwing either an engineer or an agent at any unexplored work means you just have to delegate the most experienced resource to, or suffer the consequences.
So there's a push for them to increase revenue per user, which brings us closer to the real cost of running these models.
At that point you are beholden to your shareholders and no longer can eschew profit in favor of ethics.
Unfortunately, I think this is the beginning of the end of Anthropic and Modei being a company and CEO you could actually get behind and believe that they were trying to do "the right thing".
It will become an increasingly more cutthroat competition between Anthropic and OpenAI (and perhaps Google eventually if they can close the gap between their frontier models and Claude/GPT) to win market share and revenue.
Perhaps Amodei will eventually leave Anthropic too and start yet another AI startup because of Anthropic's seemingly inevitable prioritization of profit over safety.
Just how if Boeing was able to release a supersonic plane that was also twice as efficient tomorrow; it'd destroy any airline that was deep in debt for its current "now worthless" planes.
No not really, you can issue two types of shares, the company founders can control a type of shares which has more voting power while other shareholders can get a different type of shares with less voting power.
Facebook, Google has something similar.
A publicly traded company is legally obligated to go against the global good.
Call me an optimist, but I'm still holding out hope that Amodei is and still can do the right thing. That hope is fading fast though.
So no matter what, if you do something lots of people like (and hence compensate you for), you will be evil.
It's a very interesting quirk of human intuition.
Can't blame someone who comes to such a conclusion about money and power.
Yet here they are, often considered on of the most evil companies on Earth. That's the interesting quirk.
Can you explain what you mean by this? I disagree but I don't understand how you think Google did this so I am very curious.
For my part, I started using the internet before Google, and I strongly hold the opinion that Google's greatest contribution to the internet was utterly destroying its peer to peer, free, open exchange model by being the largest proponent of centralizing and corporatizing the web.
I was about to call it reselling but so many startups with their fingers in the tech startup pie offer containerised cloud compute akin to a loss leader. Harking back to the old days of buying clock time on a mainframe except you're getting it for free for a while.
Like, Apple computers are already quite pricey -- $1000 or $2000 or so for a decent one. But you can spec up one that’s a bit better (not really that much better) and they’ll charge you $10K, $20K, $30K. Some customers want that and many are willing to pay for it.
Is there an equivalent ultra-high-end LLM you can have if you’re willing to pay? Or does it not exist because it would cost too much to train?
I guess at the time that was GPT-4.5. I don't think people used it a lot because it was crazy expensive, and not that much better than the rest of the crop.
So, for agentic workflows - ones where the model gets feedback from tools, etc…, fast enough is important.
I'd rather be surprised if they are still doing business by then.
I’m guessing we’re gonna have a world like working on cars - most people won’t have expensive tools (ex a full hydraulic lift) for personal stuff, they are gonna have to make do with lesser tools.
i bought a $3k AMD395+ under the Sam Altman price hike and its got a local model that readily accomplishes medial tasks.
theres a ceiling to these price hikes because open weights will keep popping up as competitors tey to advertise their wares.
sure, we POV different capabilities but theres definitely not that much cash in propfietary models for their indererminance
Or they are just not willing to burn obscene levels of capital like OpenAI.
The key question is how well it a given model does the work, which is a lot harder to measure. But I think token costs are still an order of magnitude below the point where a US-based developer using AI for coding should be asking questions about price; at current price points, the cost/benefit question is dominated by what makes the best use of your limited time as an engineer.
We already shipped 3 things this year built using Claude. The biggest one was porting two native apps into one react native app - which was originally estimated to be a 6-7 month project for a 9 FTE team, and ended up being a 2 months project with 2 people. To me, the economic value of a claude subscription used right is in the range of 10-40k eur, depending on the type of work and the developer driving it. If Anthropic jacked the prices 100x today, I'd still buy the licenses for my guys.
Edit: ok, if they charged 20k per month per seat I'd also start benchmarking the alternatives and local models, but for my business case, running a 700M budget, Claude brings disproportionate benefis, not just in time saved in developer costs, but also faster shipping times, reduced friction between various product and business teams, and so on. For the first time we generally say 'yes' to whichever frivolities our product teams come up with, and thats a nice feeling.
In my experience, even Claude 4.6's output can't be trusted blindly it'll write flawed code and would write tests that would be testing that flawed code giving false sense of confidence and accomplishment only to be revealed upon closer inspection later.
Additionally - it's age old known fact that code is always easier to write (even prior to AI) but is always tenfold difficult to read and understand (even if you were the original author yourself) so I'm not so sure this much generative output from probabilistic models would have been so flawless that nobody needs to read and understand that code.
Too good to be true.
I remember how website security was before frameworks like Django and ROR added default security features. I think we will see something similar with coding agents, that just will run skills/checks/mcps/... that focus have performance, security, resource management, ... built in.
I have done this myself. For all apps I build I have linters, static code analyzers, etc running at the end of each session. It's cheapest default in a very strict mode. Cleans up most of the obvious stuff almost for free.
Let's say you dont review. Those two extra months probably turns into four extra months of finding bugs and stuff. Still 8 man months vs 54.
Of course this is all assuming that the original estimates were correct. IME building stuff using AI in greenfield projects is gold. But using AI in brownfield projects is only useful if you primarily use AI to chat to your codebase and to make specific scoped changes, and not actually make large changes.
So a service ran at a loss now could be high margin on new chips in a year. We also don’t really know that they are losing money on the 200/ month subscriptions just that they are compute constrained.
If prices increase might be because of a supply crunch than due to unit economics.
It is like comparing an 8K display to a 16K display because at normal viewing distance, the difference is imperceptible, but 16K comes at significant premium.
The same applies to intelligence. Sure, some users might register a meaningful bump, but if 99% can't tell the difference in their day-to-day work, does it matter?
A 20-30% cost increase needs to deliver a proportional leap in perceivable value.
This is also why I don't see the models getting commoditized anytime soon - the dimensionality of LLM output that is economically relevant keeps growing linearly for coding (therefore the possibility space of LLM outputs grows exponentially) which keeps the frontier nontrivial and thus not commoditized.
In contrast, there is not much demand for 100 page articles written by LLMs in response to basic conversational questions, therefore the models are basically commoditized at answering conversational questions because they have already saturated the difficulty/usefulness curve.
Doubt. Yes. there was at one point it suddenly became useful to write code in a general sense. I have seen almost no improvement in department of architecting, operations and gaslighting. In fact gaslighting has gotten worse. Entire output based on wrong assumption that it hid, almost intentionally. And I had to create very dedicated, non-agentic tools to combat this.
And all of this with latest Opus line.
Lately I've been wondering too just how large these proprietary "ultra powerful frontier models" really are. It wouldn't shock me if the default models aren't actually just some kind of crazy MoE thing with only a very small number of active params but a huge pool of experts to draw from for world knowledge.
I am getting 10tok/sec on a 27B of Qwen3.5 (thinking, Q4, 18GB) on an M4/32GB Mac Mini. It’s slow.
For a 9B (much smaller, non-thinking) I am getting 30tok/sec, which is fast enough for regular use if you need something from the training data (like how to use grep or Hemingways favorite cocktail).
I’m using LMStudio, which is very easy and free (beer).
If I can get the performance I'm seeing out of free models on a 6-year-old Macbook Pro M1, it's a sign of things to come.
Frontier models will have their place for 1) extensive integrations and tooling and 2) massive context windows. But I could see a very real local-first near future where a good portion of compute and inference is run locally and only goes to a frontier model as needed.
If Claude understood what you mean better without you having to over explain it would be an improvement
For coding though, there is kind of no limit to the complexity of software. The more invariants and potential interactions the model can be aware of, the better presumably. It can handle larger codebases. Probably past the point where humans could work on said codebases unassisted (which brings other potential problems).
For summarizing creative writing, I've found Opus and Gemini 3 pro are still only okay and actively bad once it gets over 15K tokens or so.
A lot of long context and attention improvements have been focused on Needle in a Haystack type scenarios, which is the opposite of what summarization needs.
And it's not that they "don't notice" it's that they physically can't distinguish finer angular separation.
You raised a good point, what's a good metric for LLM performance? There's surely all the benchmarks out there, but aren't they one and done? Usually at release? What keeps checking the performance of those models. At this point it's just by feel. People say models have been dumbed down, and that's it.
I think the actual future is open source models. Problem is, they don't have the huge marketing budget Anthropic or OpenAI does.
It doesn't matter if a model is e.g. 30% cheaper to use than another (token-wise) but I need to burn 2x more tokens to get the same acceptable result.
Until it's making 100k decisions a day and many are dependent on previous results.
It's not necessary a single discrete point I think. In my experience, it's tied to the quality/power of your harness and tooling. More powerful tooling has made revealed differences between models that were previously not easy to notice. This matches your display analogy, because I'm essentially saying that the point at which display resolution improvements are imperceptible matters on how far you sit.
I was always wondering where that breaking point for cost/peformance is for displays. I use 4K 27” and it’s noticeably much better for text than 1440p@27 but no idea if the next/ and final stop is 6k or 8k?
I switched to the Studio Display XDR and it is noticeably better than my 4k displays and my 1440p displays feel positively ancient and near unusable for text.
You mean a couple of years ago?
claude code on opus continuously = whole bill. different measurement.
haiku 4.5 is good enough for fanout. opus earns it on synthesis where you need long context + complex problem solving under constraints
https://docs.github.com/fr/copilot/reference/ai-models/suppo...
At 7.5x for 4.7, heck no. It isn't even clear it is an upgrade over Opus 4.6.
Opus 4.5 and 4.6 will be removed very soon.
So what is your contingency plan?
> Over the coming weeks, Opus 4.7 will replace Opus 4.5 and Opus 4.6 in the model picker for Copilot Pro+.
> This model is launching with a 7.5× premium request multiplier as part of promotional pricing until April 30th
TBF, it's a rumour that they are switching to per-token price in May, but it's from an insider (apparently), and seeing how good of a deal the current per-request pricing is, everyone expects them to bump prices sometime soon or switch to per-token pricing.
It's a very good model for a very good price
When pushed it did the 'ol "whoopsie, silly me"; turned out the hallucination had been flagged by the agent and ignored by Opus.
Makes it hard to trust it, which sucks as it's a heavy part of my workflow.
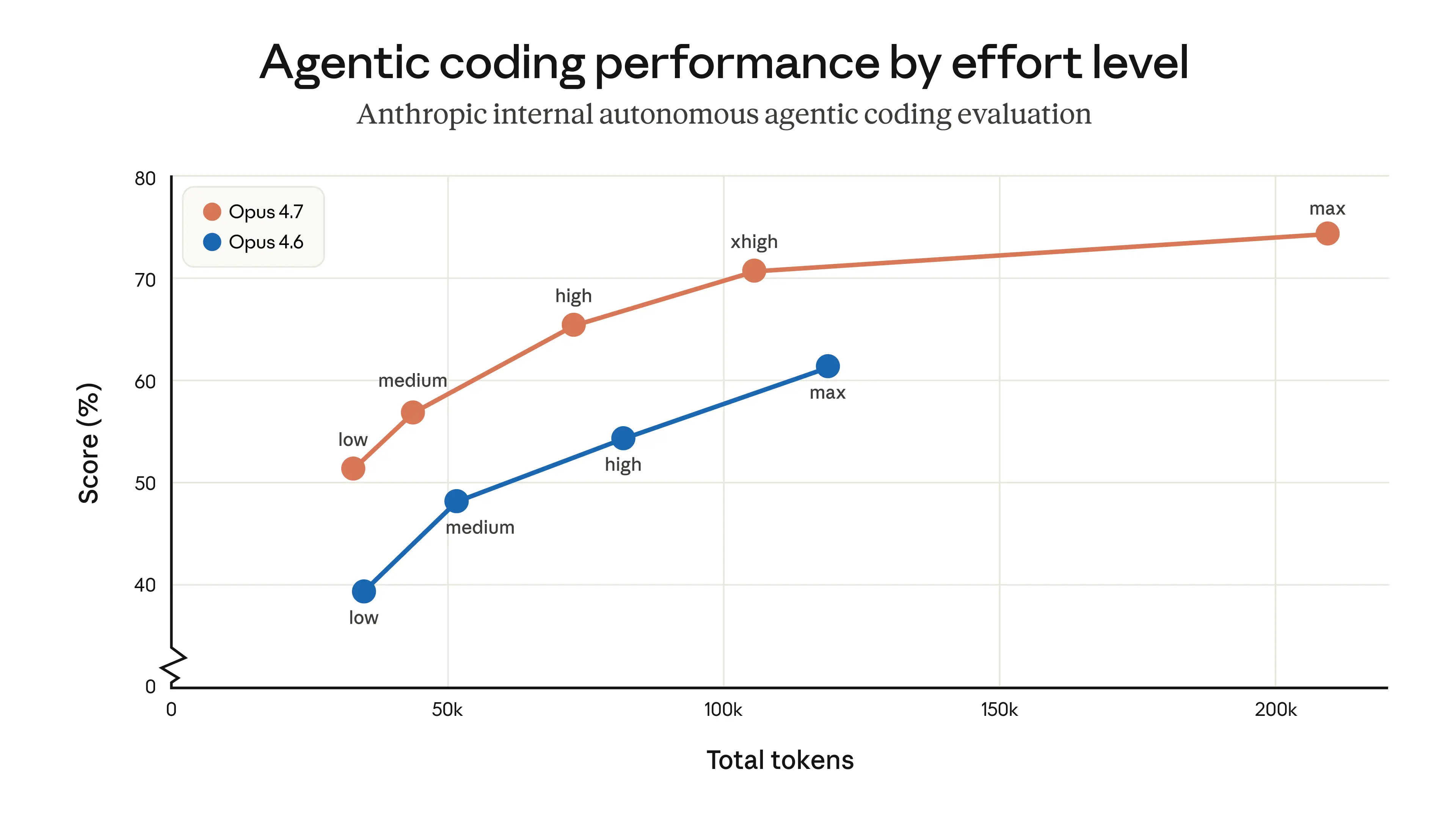
The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6. I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.
Progress. /s
> Progress. /s
pretty much, lmao. my theory is 4.6 started thinking less to save compute for 4.7 release. but who knows what's going on at anthropic
People at Anthropic, of course
"given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.”
Opus 4.7 in general is more expensive for similar usage. Now we can argue that is provides better performance all else being equal but I haven’t been able to see that
https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
1. In my own use, since 1 Apr this month, very heavy coding:
> 472.8K Input Tokens +299.3M cached > 2.2M Output Tokens
My workloads generate ~5x more output than input, and output tokens cost 5x more per token... output dominates my bill at roughly 25x the cost of input. (Even more so when you consider cache hits!) If Opus 4.7 was more efficient with reasoning (and thus output), I'd likely save considerable money (were I paying per-token).
2. Anthropic's benchmarks DO show strictly-better (granted they are Anthropic's benchmarks, so salt may be needed) https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
I think a big issue with the industry right now is it's constantly chasing higher performing models and that comes at the cost of everything else. What I would love to see in the next few years is all these frontier AI labs go from just trying to create the most powerful model at any cost to actually making the whole thing sustainable and focusing on efficiency.
The GPT-3 era was a taste of what the future could hold but those models were toys compare to what we have today. We saw real gains during the GPT-4 / Claude 3 era where they could start being used as tools but required quite a bit of oversight. Now in the GPT-5 / Claude 4 era I don't really think we need to go much further and start focusing on efficiency and sustainability.
What I would love the industry to start focusing on in the next few years is not on the high end but the low end. Focus on making the 0.5B - 1B parameter models better for specific tasks. I'm currently experimenting with fine-tuning 0.5B models for very specific tasks and long term I think that's the future of AI.
If you can forgive the obviously-AI-generated writing, [CPUs Aren't Dead](https://seqpu.com/CPUsArentDead) makes an interesting point on AI progress: Google's latest, smallest Gemma model (Gemma 4 E2B), which can run on a cell phone, outperforms GPT-3.5-turbo. Granted, this factoid is based on `MT-Bench` performance, a benchmark from 2023 which I assume to be both fully saturated and leaked into the training data for modern LLMs. However, cross-referencing [Artificial Analysis' Intelligence Index](https://artificialanalysis.ai/models?models=gemma-4-e2b-non-...) suggests that indeed the latest 2B open-weights models are capable of matching or beating 175B models from 3-4 years ago. Perhaps more impressive, [Gemma 4 E4B matches or beats GPT-4o](https://artificialanalysis.ai/models?models=gemma-4-e4b%2Cge...) on many benchmarks.
If this trend continues, perhaps we'll have the capabilities of today's best models available to reasonably run on our laptops!
I'm not seeing that in my testing, but these opinions are all vibe based anyway.
I personally think the whole "the newest model is crazy! You've gotta use X (insert most expensive model)" Is just FOMO and marketing-prone people just parroting whatever they've seen in the news or online.
Surely you can see the first lab that solves this gains a massive advantage?
Human psychology is surprisingly similar, and same pattern comes across domains.
I didn't buy Springles chips in years, even the box now is nothing like it was. Thinner. Shorter. I imagine how far from the top the slices stack up.
Today we are almost on non-speaking terms. I'm asking it to do some simple stuff and he's making incredible stupid mistakes:
This is the third time that I have to ask you to remove the issue that was there for more than 20 hours. What is going on here?
| # | Time | Gap before | Session span | API calls |
|---|----------|-----------|--------------|-----------|
| 1 | 15:51:13 | 8s | <1m | 1 |
| 2 | 15:54:35 | 48s | 37m | 51 |
| 3 | 16:33:33 | 2s | 19m | 42 |
| 4 | 16:53:44 | 1s | 9m | 30 |
| 5 | 17:04:37 | 1s | 17m | 30 |
# — sequential compaction event number, ordered by time.
Time — timestamp of the first API call in the resumed session, i.e. when the new context (carrying the compaction summary) was first sent to the
model.
Gap before — time between the last API call of the prior session and the first call of this one. Includes any compaction processing time plus user
think time between the two sessions.
Session span — how long this compaction-resumed session ran, from its first API call to its last before the next compaction (or end of session).
API calls — total number of API requests made during this resumed session. Each tool use, each reply, each intermediate step = one request.
I'm curious, how does using more tokens save compute?
Too many signs between the sudden jump in TPS (biggest smoking gun for me), new tokenenizer, commentary about Project Mythos from Ant employees, etc.
It looks like their new Sonnet was good enough to be labeled Opus and their new Opus was good enough to be labeled Mythos.
They'll probably continue post-training and release a more polished version as Opus 5
both Anthropic and OpenAI quantize their models a few weeks after release. they'd never admit it out loud, but it's more or less common knowledge now. no one has enough compute.
Tons of conspiracy theories and accusations.
I've never seen any compelling studies(or raw data even) to back any of it up.
https://arxiv.org/pdf/2307.09009
but of course, this isn't a written statement by a corporate spokespersyn. I don't think that breweries make such statements when they water their beer either.
The only misprediction it makes is that AI is creating the brain dead user base...
You have to hook your customers before you reel them in!
https://www.netflix.com/gb/title/70264888?s=a&trkid=13747225...
> You're right, that was a shit explanation. Let me go look at what V1 MTBL actually is before I try again.
> Got it — I read the V1 code this time instead of guessing. Turns out my first take was wrong in an important way. Let me redo this in English.
:facepalm:
Does the LLM even keep a (self-accessible) record of previous internal actions to make this assertion believable, or is this yet another confabulation?
The weird stuff is yesterday I asked it to test and report back on a 30+ commit branch for a PR and it did that flawlessly.
Claude and other LLMs do not have a gender; they are not a “he”. Your LLM is a pile of weights, prompts, and a harness; anthropomorphising like this is getting in the way.
You’re experiencing what happens when you sample repeatedly from a distribution. Given enough samples the probability of an eventual bad session is 100%.
Just clear the context, roll back, and go again. This is part of the job.
> max: Max effort can deliver performance gains in some use cases, but may show diminishing returns from increased token usage. This setting can also sometimes be prone to overthinking. We recommend testing max effort for intelligence-demanding tasks.
> xhigh (new): Extra high effort is the best setting for most coding and agentic use cases
Ref: https://platform.claude.com/docs/en/build-with-claude/prompt...
{kind=link}