Posted by salkahfi 2 hours ago
> GitHub Will Prioritize Migrating to Azure Over Feature Development - GitHub is working on migrating all of its infrastructure to Azure, even though this means it'll have to delay some feature development.
> In a message to GitHub’s staff, CTO Vladimir Fedorov notes that GitHub is constrained on capacity in its Virginia data center. “It’s existential for us to keep up with the demands of AI and Copilot, which are changing how people use GitHub,” he writes.
https://thenewstack.io/github-will-prioritize-migrating-to-a...
So the currently delayed feature development is now gonna be further delayed, yet almost every week we see new features and changes, just the other day the single issues view was changed, as just one example. And it was "existential" 6 months ago yet they keep stumbling on the exact same issue today?
Even if they're focused exclusively on reliability and uptime, we get the experience that we have today, kind of incredible how a company with the resources of Microsoft seemingly are unable to stop continuously shot themselves in the foot. It's kind of impressive actually. As icing on the cake, they've decided to buy up all popular developer services then migrate them all to the same platform, great idea too.
They did that as a panic mode hack to mitigate performance: https://news.ycombinator.com/item?id=47912521
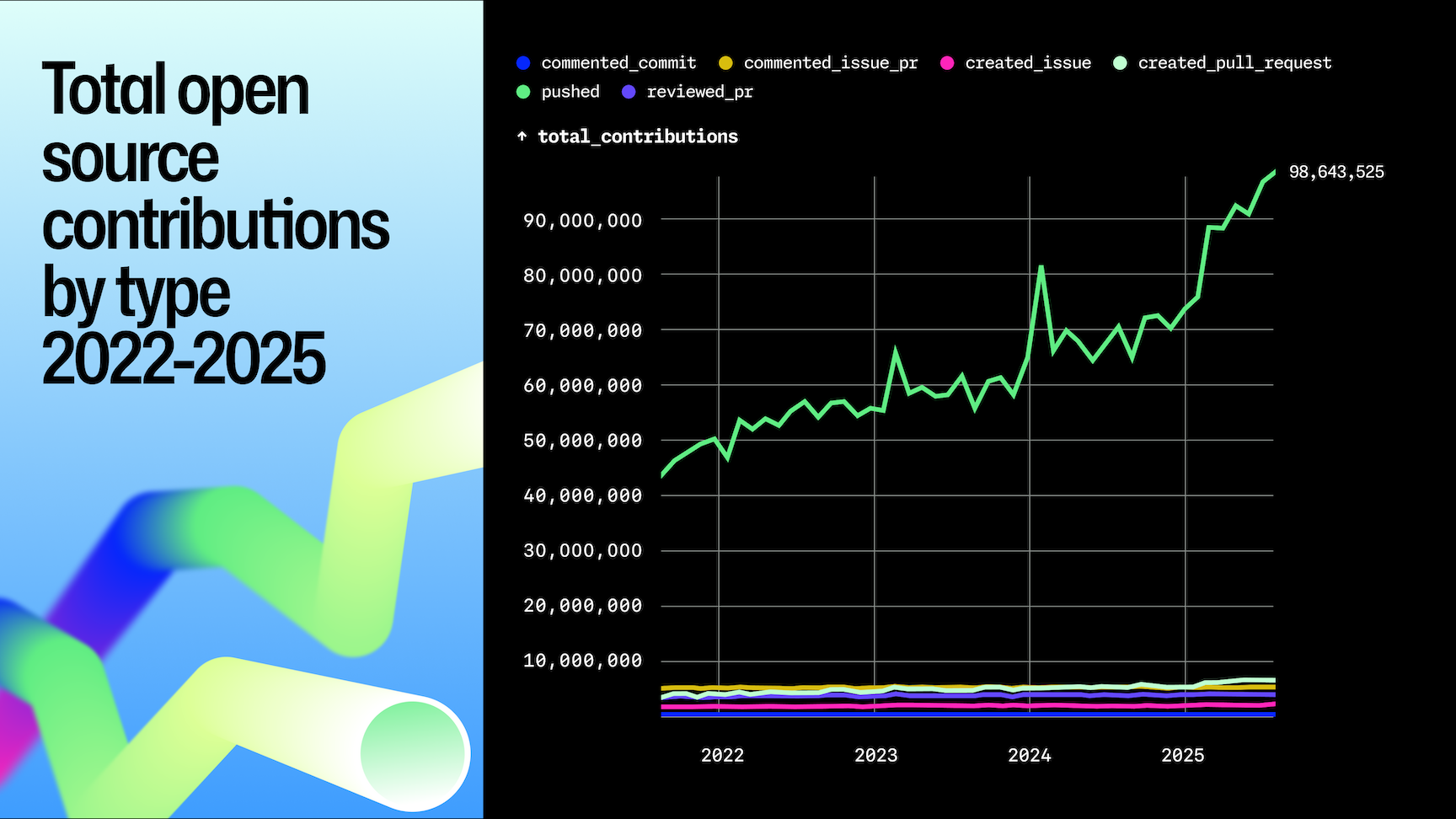
The unlabelled graph with big numbers on top, the priorities that don't match with what we're experiencing, and a list of things that they're doing without a real acknowledgement of the _dire_ uptime over the last 12 months....
You don't need to know the bottom left axis number. We do have to assume the graph is linear, and not some kind of negative exponent log graph. But given the rest of the content, I think that is safe to assume.
Any company that experiences significantly more growth than they were planning for will have capacity issues.
The priorities are most inline with that. The are way beyond the point that they can just add more hardware. They need to make the backend more efficient, and all the stated goals are about helping there.
We very much do. The graph suggests an insane growth in PRs from almost zero to 90M. Now compare this misleading graph with this much clearer one, which shows that the growth over the last three years has been less than 80%: https://github.blog/wp-content/uploads/2025/10/octoverse-202...
No, they're completely useless. Using the "New repos per month" as an example, if the bottom left is 1m, then that's a 20x increase in 2 years which is a lot. If the bottom left is 19m, it's a 5% increase in 2 years which is nothing.
The massive surge on their labelled X axis starts in 2026, and these issues have been going on for a lot longer than that. GHA has been borderline unusable for a year at this point, if not longer.
> But given the rest of the content, I think that is safe to assume.
The rest of the content is "we're working on it", and "here's two outages in the last 14 days, one of which caused actual data loss"
What's the question here, you don't believe growth is currently exponential, or do you think it shouldn't be hard to scale, when 10x YoY is not enough?
I’m sure they’re experiencing scaling issues across the platform, but it’s unacceptable for that to have a negative impact on us when we're sending them $250/dev/yr for (what is in all honesty) hosting a bunch of static text files.
But if anything, their post and your reply are precisely an endorsement of usage based billing.
The bit that's growing 13x YoY (and which they expect will easily blow past that) is unmetered - commits. The bit that is metered (for some, not all folks) - action minutes, grew only 2x YoY.
GitHub was not built to limit the number of commits, checkouts, forks, issues, PRs, etc - nor do we want them to - but that's what's growing ridiculously as people unleash hordes of busy beaver agents on GitHub, because their either free or unlimited.
Where there are limits - or usage based billing - people add guardrails and find optimizations.
Because for all the talk, agents don't bring a 10x value increase; otherwise, they'd justify a 10x cost increase.
Besides, other forges are having issues too. Even running your own. We have Anubis everywhere protecting them for a reason.
You know, you can just host your own code forge. Or you can just drop gitolite on a server. Or pull directly from each others' dev machines on a LAN.
GitHub is not git.
so start a GitHub competitor which bills $50/dev/yr for solving this easy problem and make a lot of money?
> What's the question here, you don't believe growth is currently exponential, or do you think it shouldn't be hard to scale
I think you're putting words in my mouth here; I didn't say either of those things. I'm saying that this blog post is a meaningless platitude when the github stability issues predate this, and that all this post says is "we hear you're having issues".
I just think their charts, taken at face value, show substantially the same thing (for PRs, commits, new repos).
Either those charts are a bald-faced lie (the tweet could be as well) or there is no way for that chart to be something else.
The only way to fake exponential growth like that would be to use an inverse log scale (which would be a bald-faced lie).
It doesn't even really matter what's the y-axis baseline, unless we really think growth was huge in 2020, then cratered to zero by 2023, now back to the previous normal.
As for the rest of the post, I do think it's panic mode platitudes. But I honestly don't know what I'd write instead that's better.
You can already see people complaining loudly where they instead of "we'll do better" decided to limit usage.
Is this microsoft stating that they aren't able to get acceptable reliability from Azure? (I mean, I think a lot of us have heard that, but it's interesting to hear it from microsoft themselves).
Then it's up to Azure how they will manage this
I guess most people at Github knew exactly it makes no sense but they didn't really have a choice. Maybe some voiced their statement, got "we hear you" in response and were told to proceed anyway.
Microsoft Execs: Everyone needs to move to Azure!
GitHub developers: But Azure is not gonna be able to handle our load, we literally have our own data centers!
Microsoft Execs: Sure, but you're Microsoft now, please publish blog post about how in half a year you'll be 100% on Azure.
Few months later...
GitHub Developer: We've tried our best, users are leaving in droves and Azure can't keep up!
Microsoft Execs: Ok fine, you can use something else too, but only if you mainly use Azure and continue publishing blog posts about how great Azure is.
Prime video does use some AWS services, but live and on-demand are two entirely different beasts.
There's no intrinsic reason they should be vulnerable to themselves.
But Github don't have that rationale.
Status page is also still doing that thing where every component is green but in practice clone is hanging, push is timing out, actions are stuck. Per-service uptime is a managed number. The user-experience number is the one that matters and it's not in the post-mortem.
GitHub is claiming they require 30x scale due to the giant increase in repository creation, PRs, commits, etc.
I have not seen a single product increase in features or quality as an end user, nor new significant products have come out in this period (other than the LLMs themselves).
Where is all this code going?
What I’m not seeing here but I am seeing with the Linux kernel is, most of the automatically submitted code is irrelevant or not useful
Half of my friends is vibe-coding something but they can barely get the rest of the group chat to use it once.
In companies, I see people vibe-coding "miracle apps" that fall under the smallest amount of scrutiny.
Basically people are doing the same developers do when they say "I can do this in a weekend", which is getting a prototype sort of running and then immediately losing energy (or in this case lacking ability) to push it forward.
Some people I know can't even explain what they are trying to create.
Stop subsidizing tokens now that we extracted enough training data from you and we have enough agentic junkies business to keep the flywheel going up and cut on the loss leaders. [0]
Looking at the commit graph: Why do commits have big steps followed by slow rolloffs? Why do the steps not happen at uniform points Why do larger steps sometimes have less of a slope than smaller steps but not all the time?
Then looking at the other graphs there's completely different effects going on.
Global indices for this should be trivial to spin up so availability is never a concern (we're working towards this!).
If I could get the same bells and whistles by wiring up another forge, so long as it offered a decent API and/or sent events over a webhook, I'd have everything self-hosted.
The agents would need to expose an interface on their own end but as long as you implemented it with a plugin, it'd take the dependency of GitHub and you could use MCP or skills for the rest of it.
Which is to say, this is perfect for agents given they don't need any bespoke SDK from us: simply write Tangled records for issues, pulls, whatever to your PDS and it'll show up on Tangled. We plan to start working on some exemplar agents first-party that would 1. enhance Tangled itself, 2. showcase cool things you can do with an open data firehose.
Disclaimer: the author is a colleague of mine
Though to be fair, what the parent meant by federated forges is different than this approach.
I'd say we have emails, mailing lists and bug trackers. Or maybe: what is the missing killer feature that needs federation?
Issues, pull requests, collaboration/permissions/access, "staring"/"favoriting", etc.
I think ultimately the goal is that people can run their own forges, yet still collaborate on repositories hosted in other forges, leveraging your existing authentication so you no longer need to sign up individually for each forge.
I recently migrated to codeberg because I'm okay with self-hosting big runners, while using codeberg's available runners for smaller cron-based things (they even have lazy runners for this).
But a VPS isn't actually infrastructure you control, you essentially have as much control over it as "cloud", so I don't think that'd be counted as "sovereign", would it?
{kind=link}