Posted by thoughtpeddler 10 hours ago
There is no secret sauce the US labs have that the Chinese ones don't, or won't have soon enough. Deepseek 4 and Kimi 2.5 are not quite Claude 4.5/GPT5.5 but there's no fundamental principle missing - they are strong evidence that there's no real advantage the "frontier" labs possess that isn't related to scale, which they will gain in time (if they even need to). The RL post-training techniques that work are widely known and easily copied. All Deepseek is really lacking is data, which they're getting - and the harder Anthropic/the USG makes it to access claude in china, the more of that precious data they'll get!
I used to sort of entertain the "fast take-off breakaway" scenario as being plausible but not really anymore. The only genuine moat the frontier labs have is their product take-up, which isn't nothing, far from it, but it's not some unbreakable technological wall. Too late guys - it might have been too late for quite some time.
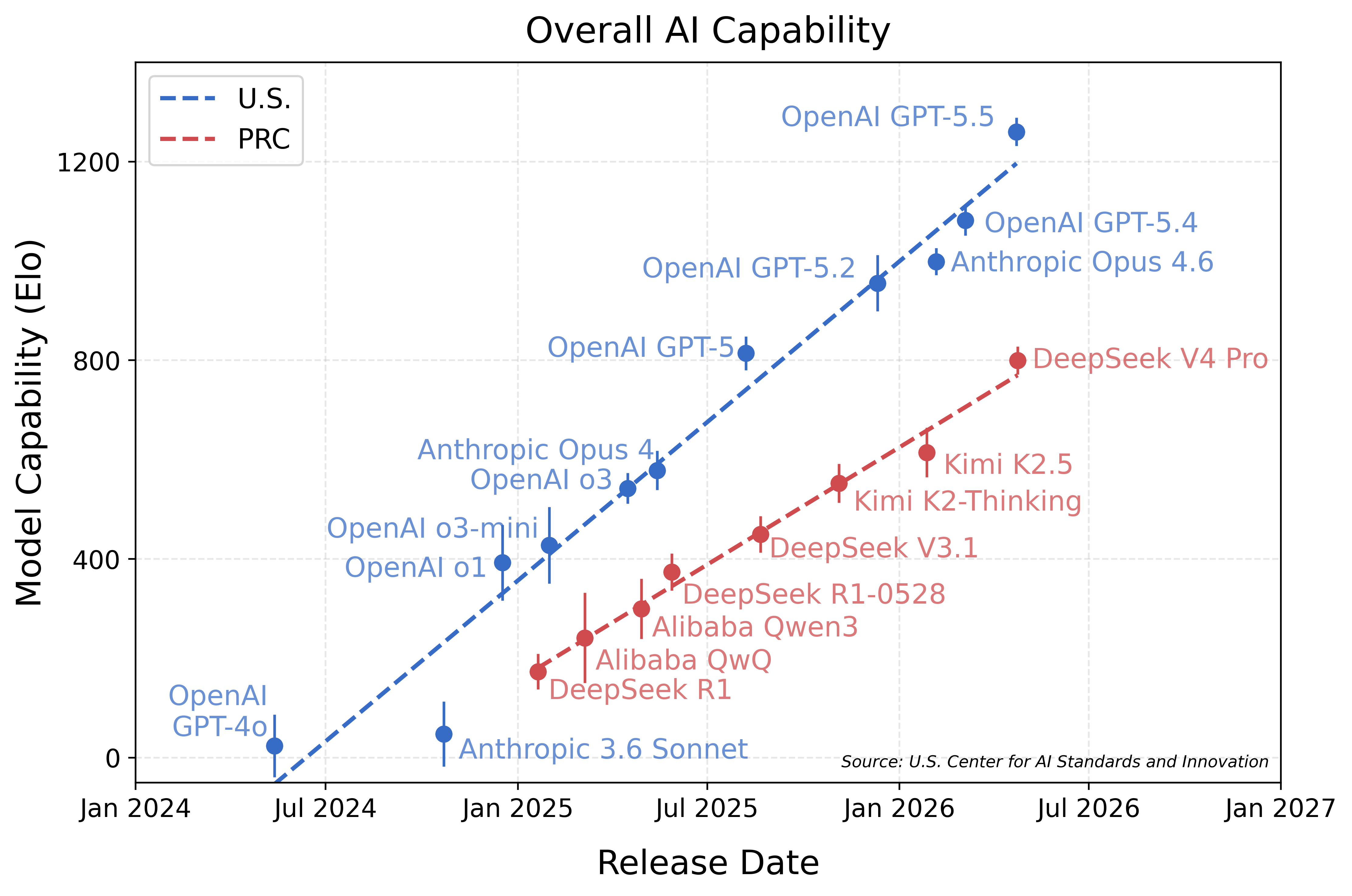
However, they just don't perform that well in practice. That's the real issue. You can actually see it when you move away from open benchmarks. Deep seek 3.2 is 4% on Arc-AGI 2 [1], while GPT 5.2 high is 52% and GPT 5.5 pro high is 84.6%. That's the real reason why nobody is using these models for serious work. It's incredibly frustrating.
In addition, I already feel the pain myself on the model restriction. I'll asking my codex 5.5 agent to crawl a website - BOOM, cybersecurity warning on my account. I'll ask it to fix SSH on my local network - another warning. I'm worried about the day my account would be randomly banned and I cannot create a new one. OpenAI already asks you to perform full identification in order to eliminate these warnings - probably exactly for that - so that if they ban you, it's permanent.
Why are you bringing up an outdated Chinese model from 6 months ago to compare to a US model from 6 months ago? The outdated Chinese model will have performance from ~12 months ago, obviously. But today's Chinese model DeepSeek 4 has performance not far from the US model 6 months ago; 46% compared to 52% from 5.2.
Kimi K2.5 has also been superseded by a finer tuned Kimi K2.6 three weeks ago. Moonshot's Kimi models appear to be the favored Chinese model, at least for coding, and not Deepseek V4. z.AI's GLM 5.1 is also worth mentioning as rather competent for coding, also released in April.
Those models too will not be beating US AI labs by your metrics (although for coding, Kimi K2.6 might beat the very uneven Gemini depending on the situation), but in your critism at least consider the state of the art in your comparisons.
The Chinese models right now are in a weird spot. Compared to the frontiers, both their pre and post training is woeful - tiny, resource constrained in every dimension including human, slow. I'd compare it to OpenAI 5 years ago except I think even then OpenAI had way more!
But they "cheat" quite a lot in distillation and very benchmark-focussed RL and that's where you get this superficial quality in the leaderboards that doesn't match up when you go off-script. Arc is a great example in that it really belies an "inferior soul" at the heart of it all.
What gives me great hope though is that those same scaling laws that Altman and others have been hyping forever will absolutely kick in for the Chinese labs just as they did for the US ones, and I don't think anything can stop that process now. So they will catch up. It won't be tomorrow, but it's not going to be 10 years either. 3-5 would be my reasonably educated guess.
And the final risk, that China itself might try to restrict availability of the tsunami of GPU or other AI hardware it will inevitably produce - well, I just can't really imagine a country that has been configuring itself for the last 40 years as a single purpose export machine deciding that actually, no, it doesn't want to export something.
About the model restrictions - absolutely. I've been trying to do security research on my own software and the frontier models immediately get suspicious. I've been playing with the local ones much more this year basically because of this. They have deficiencies, for sure - they feel very "hollow" compared to the major labs. But I've talked to a lot of people, and the consensus is pretty clear - just a matter of time.
It definitely 'feels like' it is as good as Claude for many regular web app coding tasks (though I don't have real benchmarks). And it is comically cheap.
I'm not suggesting it is better than the latest Claude or codex models, but it seems 'good enough' for a lot of use cases in my limited real world testing.
Benchmarks are not very good at capturing this yet. But it could be the case that DeepSeek v4 Pro is 100% as good as Claude Opus 4.7 at scaffolding a basic Rails app, but absolutely terrible at creating a credible business plan that another businessperson would think is real. That's a made-up example, but you get the point.
The end result will be a lot of people arguing about which model is "better," but "better" depends heavily on the task and how that model was trained to interact with the user for that task. Two users may have very different qualitative experiences using the exact same model, despite the benchmarks.
I've just written a blog post about this topic this week: https://octigen.com/blog/posts/2026-05-11-ai-presentation-ga...
I don't think every dev will be comfortable just releasing claude on their project.
This shows that AI cloud consumption is just a conspicuous consumption status symbol, nobody knows why they need cloud AI or what problem they are even solving.
The economic pressures are the same, too. Currently, Chinese models are offered for cheap or in some cases provide weights for free because that's the only way to gain traction. (That closed-weight releases by Baidu, Bytedance, iFlyTek etc. hardly generate any buzz bears that out, as does the fact that when Alibaba does a closed-weight release, someone always gets confused because they associate the Qwen brand with open models.) At some point, their investors are going to want profits, not just user counts. That means higher prices, or no more new models.
If there's no secret sauce and all you need is scale, that would actually be kind of the worst-case scenario for catching up to the frontier, since scaling is expensive and the frontier model companies have easier access to capital as well as higher revenues.
They aren't trying to become that good, nor do they need to in order to have real positive impact. Models like Mythos are estimated to be humongous even on a datacenter-wide scale, which is actually a big factor in its limited availability at present. It's mostly helpful as a one-of-a-kind proof of concept, to answer the question of whether AI can still plausibly scale by growing capabilities and what happens to alignment concerns when you do that.
Data governance and enterprise sales is a moat. The harnesses aren’t.
But 1) people use other models with that same harness. 2) I moved on from Claude Code and all the features I cared for up and running in less than a couple days. Without even looking for available plugins or extensions.
I mean, if that’s the case, then Anthropic themselves are currently actively filling in that moat with nice, solid, walkable dirt. Claude Code may have been a moat 6 months ago but these days you’ll want to replace the “m” with a “bl”.
> just like there’s more market share by MacOS+WindowsOS over Linux Open Source.
It's hard to change OS. It's not hard to jump from one AI tool to another
Likewise Qwen 3.6 absolutely blows me away and that’s on a 35b 6-bit model on a local 5090. Same thing, busy trying to find stuff to do to keep it busy 24/7.
I can still find some niches for Opus 4.7 but being able to attack problems and not worry about consumption is a game changer.
I will say, as pointed out by others, DeepSeek and other Chinese providers still lack a bit in the tooling that Claude has, but they'll get there.
Even assuming this holds, what utility you gain by the best models depend completely by your workload. If you have tasks that require performance 10 and DeepSeek has 9, you will gladly pay for SotA models.
All of that will all be legacy in a couple of years. Today's B200 clusters are tomorrow's e-waste. Decentralization might happen gradually or abruptly. But to me it's obvious that we'll be thinking of high-tech tensor processors and GPUs the way we thought of individual transistors and tube amplifiers in the 1980s.
If AI turns out to be the revolution it purports to be, than the underlying hardware will change much more rapidly than it did with ICs and microprocessors in the late 1970s. Today's hot is tomorrow's junk.
No reason to expect Moore's observation to apply there (though, maybe?), but it will have big implications for power usage.
Hardware depreciation timescales are actually getting longer, not shorter, because frontier hardware like B200 clusters is highly bottlenecked. It's not just a RAMpocalypse out there, we're seeing early signs of production bottlenecks with GPUs and maybe even CPUs.
And even then, their is no stickiness. For most use cases there isn’t much value in one frontier model over the other.
Just have to look at the people flocking from one to the other for whatever reason.
The point isn’t that gpt is better, it’s that it is so much better for my work it isn’t even sticky, it’s reinforced concrete. I use opus 1% of the time because it writes better and it’s sticky there.
Yes I’ll switch approximately immediately if opus or Gemini (which I use more than opus!) is better for what I do, but at this point frontier model tokens are not fungible.
Over last year it seems that the only thing US labs are ahead is money spent. At least half of technical innovations if not more came from Chinese labs and was published openly.
This is not just about mainland China though. The current US government is extremely selfish and self-centered. Other countries really need to consider for their own long-term situation here.
Also, he concedes Mythos-level capabilities will be cheap next year, then handwaves it with "you need the best AI, not good-enough AI." For most use cases, frontier minus six months is fine.
At the end of the day, as a consumer, you still pay per token (or per something) to your provider, except you can chose from multiple providers with your own criteria. If you want to use DeepSeek v4 hosted in Europe, it's possible.
Open models that are competitive with frontier will be used on shared hosts.
And with the extreme chip shortages for the next two years, there's little appetite for even bigger models anyway.
Barring a breakthrough in scaling, the only direction the models can really go is smaller. Which will inevitably mean better performing local models for same chip budget.
You can always run these models cheaper locally if you're willing to compromise on total throughput and speed of inference. For most end-user or small-scale business needs, you don't really need a lot of either.
Before you challenge with benchmarks, consider the labs which release open weight models have internal testing and unpublished results.
1. Your European startup will be competing with others using a much better frontier model. In a scenario where you already have other major disadvantages (access to capital, labor), you might be outcompeted
2. Open models have been keeping pace very nicely, but they rely on distillation of frontier models. If the race gets really tight, this could be affected so that the time gap grows larger (ie, it's very unlikely anyone but Anthropic is distilling from Mythos at the moment)
If the small (and I'd even say, sometimes imperceptible) difference between Opus & DeepSeek v4 Pro is such a disadvantage for your startup, it's that your startup have an issue, not the LLM.
At the end of the day, your startup is there to solve real problems and even before the LLMs, being fast at coding things have never been such a huge competitive advantage compared to marketing, sales, customer support, product vision ...
Besides, if the difference between Opus and DeepSeek 4 is so small and imperceptible, you are missing the opportunity to launch a startup on your own and compete with Claude Code.
Update: GPT-5.5 found it.
Article: https://www.nist.gov/news-events/news/2026/05/caisi-evaluati...
Graph: https://www.nist.gov/sites/default/files/images/2026/05/01/1...
If the Chinese government published a graph that said the opposite, would you consider that a serious and objective source?
edit: I'm specifically referring to the "5.5 Pro" model, not regular 5.5 with Pro tier subscription. Claude has no model available that's comparable to 5.5 Pro either.
The thing is, vast majority of code tasks aren’t a venture into the unknown. We as an industry for the most part build CRUD interfaces and dashboards. That can be achieved, with supervision, with frontier open-weights models quite well.
Well, yes, someone probably will do that. But I’m pretty sure there will be consequences for the engineer errors in this vibe-calculations.
(tap view all on yr link or ask gpt to search for you next time)
This works for us and will work for years to come. It is not SOTA, but it works darn well for our purposes, and we control the compute and data flowing through it, so totally worth it.
In other words, if AI does have continued significant economic impact, only the US and China would be able to leverage it completely. The rest of the world is implicitly betting that AI won't be good enough, or that eventually the compute curve flattens out so using a model that is 10x larger only leads to marginal benefits.
Is it even though? Quantization and speculative decoding are improving the local AI story by leaps and bounds every month.
All these tricks like quantization and speculative decoding can also be used by the leading AI labs, which means they will simply have more compute than you at the end of the day. So far this has translated into better performance.
There's also an additional economic concern that rarely gets mentioned: because no one has cracked continual learning, keeping models up-to-date and filling in gaps in performance requires retraining on an ever growing dataset. Granted, you aren't starting from scratch each time, but the scaling required just to stay relevant looks daunting.
I don't know where any this goes on a societal level, but I've believed since the release of deepseek r1 that access to frontier models would eventually be locked up behind contracts, since the only moats protecting the models themselves are purely artificial. It remains to be seen how effective China is at pushing the envelope, and whether they are interested in providing unfettered access. And on top of that, it remains to be seen how well these models actually turn out to scale in the long run.
The question is whether this same model can successfully be applied in disciplines like medicine, law, engineering, etc.
Ultimately it's a resource control issue. To power AI you need land/space (to build on), water, energy, and lots of hardware. Hardware needs to be manufactured and engineered. It needs metals, some exotic materials, machines, etc. More resources in other words. If you look at China vs US here, they are really well positioned in terms of resources and supply chains. The US has fallen behind quite a bit on energy and all the critical resources needed to produce hardware. AI is bottle necked on a lot of stuff that China has or makes in abundance.
For the frontier models, there are a growing number of companies and countries that provide them. We're used to mostly talking about the US ones. But of course the Chinese have a lot of capability here and they are not that far behind. And that's judging by the models they choose to release under OSS licenses. Those models are not their frontier models. And there are a lot of other countries developing and using models that aren't necessarily talking openly about what they are doing.
The irony with these frontier models is that they only generate revenue if people can use them. Why sink billions in AI infrastructure and models without a revenue model?
The reality with Mythos is that you have to assume that the Chinese (and others) are not that far behind and may already be running an equivalent model that they just haven't told anyone about yet. Anthropic gate keeping Mythos and its findings is probably wise. But it's not long term sustainable to depend on that happening or working very well. Or even on them even being a leader in this space.
This is becoming an arms race between countries, and economies. And it's an economical and resource control race. Developing and researching in the open has advanced things massively. But it has also empowered the rest of the world. Both Anthropic and OpenAI are staffed with people from all over the world. You have to assume that they probably aren't very good at keeping things secret.
But if progress keeps going I'm sure it will get to the point where my brain doesn't feel sick after watching it. I hope so, because I'm sure there's a lot of AI videos in my future, whether I want them or not.
There’s no narrative, there’s now sense of reality, it’s just a sense of here’s a million pixels of colours that have proven to go well with each other, it’s _slop_.
It’s been years and the only place AI has conquered in visual entertainment is as a subpar Photoshop replacement to fill in the B-roll gaps for those that don’t have the patience or money to do it the proper way.
Physics.
{kind=link}