They continue to focus on smaller models while openai and anthropic are increasing compute requirements for their SOTA models.
I wish google just came out and told us how large their flash model is, because if it's as big or smaller than gpt-5.4-nano that's the real headline here.
Can you link to a source?
They are just refining their current models while they finish training the next generation.
They will all come out at about the same time. Anthropic, OpenAi, Google, xAI
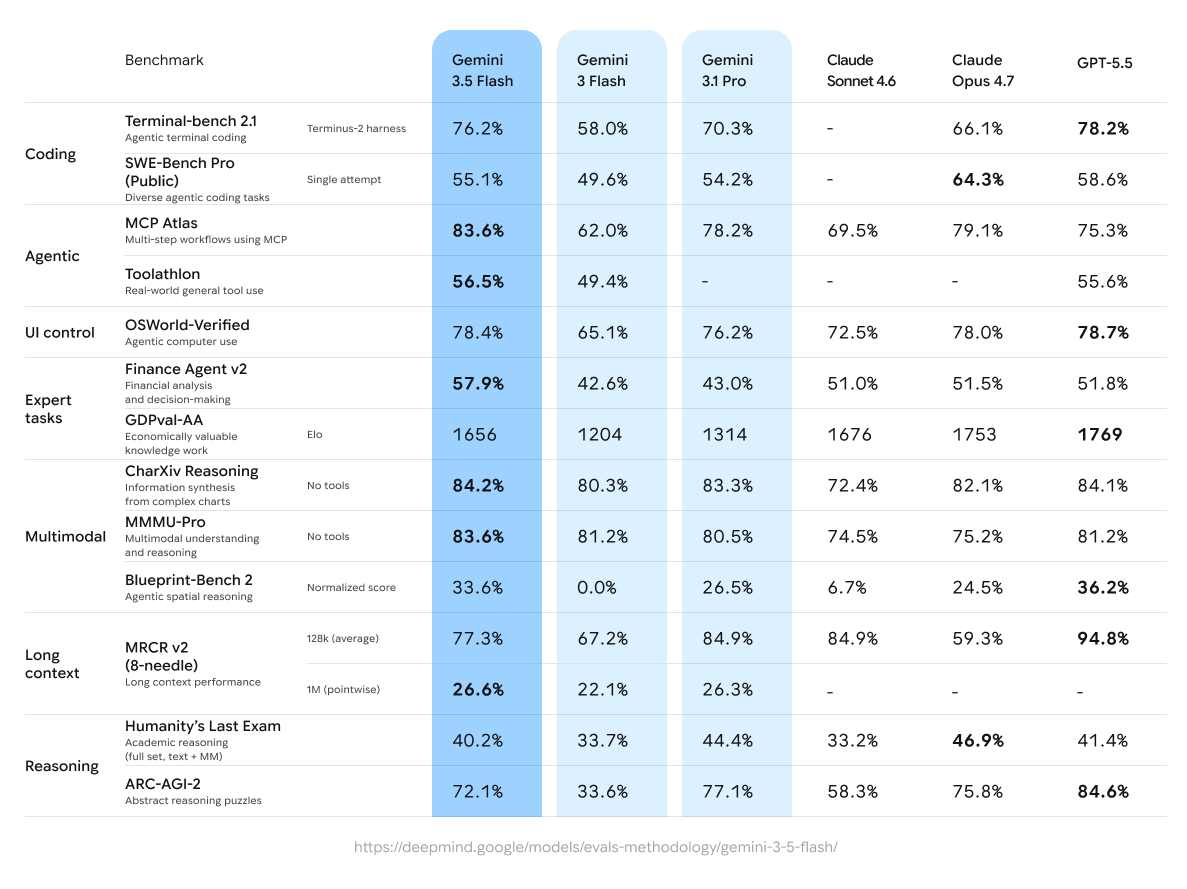
Hold on, I think this claim needs some hard data. Here you go gentlemen:
https://www.aisi.gov.uk/blog/our-evaluation-of-openais-gpt-5...
There might be a harness difference, but also, this CTF-type benchmark might not capture the capability difference fully.
For intelligence/size only OpenAI and Anthropic are the frontier. Google has more compute so it can compensate for that with size of the models...
Nobody really knows the answer to which one is more optimal
* Large model trained on a large amount of data across multiple domains, that doesn't need any extra content to answer questions.
* Smaller model that is smart enough to go fetch extra relevant content, and then operate on essentially "reformatting" the context into an answer.
Google: we don’t need Chinese to distill our models, we can do it ourself
https://storage.googleapis.com/gweb-uniblog-publish-prod/ori...
Source: https://developers.googleblog.com/an-important-update-transi...
At least it read the authors of the article to me.
I wish we would push more towards testing code. Agentic AI excel when it's engaged.
> Gemini 3.5 Flash’s pricing shifts the Pareto frontier in Text. 8 models from GoogleDeepMind dominate the Text Arena Pareto curve where only 4 labs are represented for top performance in their price tiers.
Artificial Analysis's "Cost to run" model (aka num_tokens_used * price_per_token) is much better, but even that is likely problematic since it's not clear whether running a bunch of benchmarks maps cleanly to real-world token use.
It’s not possible to uptrain on preview releases and it did not get that much love for a while.
{kind=link}