at notion we use redis for a lot of things, but actual caching we leave to memcached
Just trying to get a sense of where people draw the line.
The most common first thing to cache is getting the current user, because this ends up being a very hot path for most stateless systems. Because you need to get the current user for almost every request, it's quite easy for getting the current user to be 50% of database load: first you get the user, then you do the thing. tada, user lookup is now half your app by volume
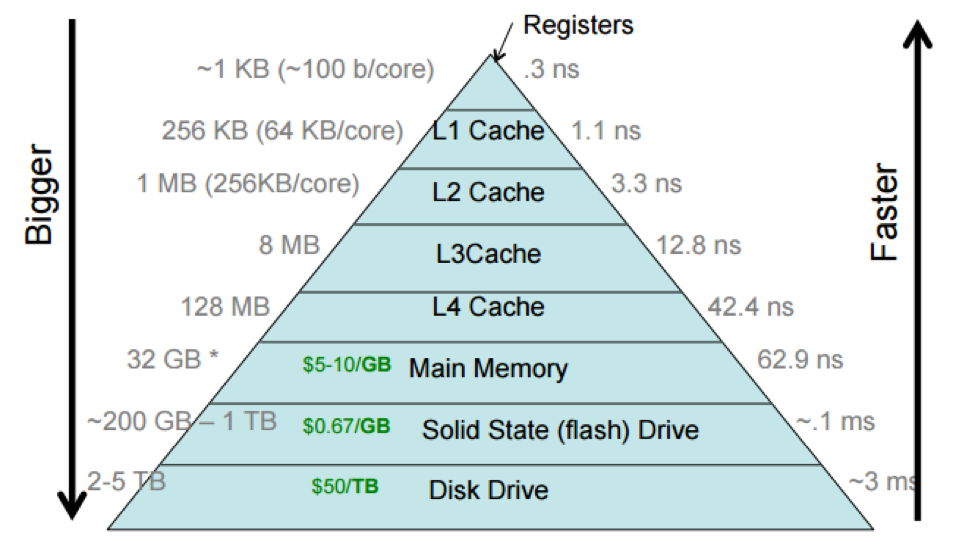
Look at this image: https://cs61.seas.harvard.edu/site/img/storage-hierarchy.png
At scale, the timing and order of magnitude increases in latency can add up. Caching the most requested data the higher you go can keep up performance (at added cost). On a busy website, that could be things like session tokens or other data that is part of every request. On a landing page, it could be images or other static data (I mean, you'd use a CDN for this, but you get the idea). Database calls can be expensive (computationally and IO wise), so if you can recalculate and cache certain operations, you can keep up.
Also, do you really need memcached/redis? If you have session affinity, you can also have nodes each keep their own caches in memory, with the caveat that if there's a failover, you'll have to re-fetch the data. Redis/memcached would be more of a shared cache, for things that you may not want to interrupt the user if they hit a different front-end endpoint.
It also doesn't have to be a cache. We've used redis for distributed task coordination as a shared state with the caveat that if something happened to redis, we'd just restart the task.
TL;DR If you need a SHARED cache when the performance of your app slows down enough that the cost of caching makes up for it.
1) Wrap your client library so that it's impossible to store anything without an expiry date. You don't want 6-months-old data suddenly coming up in your app!
2) Either turn off persistence, or use a separate database for the cache. In other words, don't mix volatile data with stuff you actually care about.
3) Set up a reasonable maxmemory value with an appropriate maxmemory-policy, so that Redis doesn't eat up all your RAM.
4) Resist the urge to use complex data structures. If you try to update a single field on an expired hash, you will end up with an incomplete object.
If you don't want all that hassle, then yes, Memcached probably works better out of the box.
No need for this client-side complexity, as you should be using `allkeys-lru`. FWIW, should likely be doing this anyway, as (generally speaking) all data stored in Redis is usually regarded as volatile because of what Redis actually is.
If you know this already, then you didn't need to read OP or any of this thread. :)
The problem is that Redis tries very hard to position itself as a persistent data store, with defaults that lean toward persistence (no default eviction policy). Beginners need to fight these defaults every step of the way if all they want is a cache.
What are you talking about? On their website, the top 3 use cases (under the Platform menu) are: caching, streaming, and session management. Literally all of these three are volatile.
One big tip I should recommend is to increase the default memory size limit to something more realistic for modern hardware (and arguably this should just be increased on the upstream's side as well, instead of making everyone reconfigure shitty defaults). It's very easy to exceed the memcached default key value, since it's just 1mb; the maximum size of memcached as a whole is 64mb, which is similarly very low. Outside of that, it works very well and the lack of persistence is great at making it not do things it's not supposed to do (which is a big problem with Redis' feature creep, the projects mainpage promoting AI drivel alone should point towards that.)
{kind=link}