Stunned to see that Gemini threw its digital arms in the air and gave up.
The latter strategy almost entirely depends on the quality of the skills and tool calls exposed to a given agent.
So let's say you have a super dull pdf ( or even a scan ) that has the same line over and over again, could this get the model into one of those loops that just keep spewing nonsense.
And thinking that further, could someone prompt inject a model with a handwritten note that only gets "activated" once it's in the context?
Some considerations:
1) tell it to extra t the data (in a new session) does that work?
2) if it doesn't, could there be something up with the PDF?
As many commentors suggested, this works well with Gemini so there is likely a missing variable in play.
Share your prompt and the PDF and let's see if we can determine what.
For regular pdfs that have been produced in a “normal way” (ie using latex or a modern application with a “save to pdf” function) will contain the text and for those I’ve had a lot of success on general pdfs using pypdf.
“Image” Pdfs that have been produced via a scan so don’t actually contain a text transcript require actual OCR. At the moment my personal rag pipeline is doing this using a local Gemma4 model (you could use something else).
Either way I do an audit post-ingest where I select a random set of pages and also get the local gemma model to try those same set and compare. The symptoms to look out for here will depend a lot on what you’re trying to extract but I’m extracting maths mostly so I get the model to check extraction of symbols, equations etc. One thing I have consistently found useful is to look for “mojibake” (scrambled text caused by decoding in an unintended character encoding) as this almost always catches pdfs that have just extracted as pure garbage. I added this step because I was ingesting a lot of old maths pdfs which have specialist notation that wasn’t always getting correctly ingested and as they were image pdfs it was coming in as pure garbage. So the fix here is to use a specialist ocr service (I have been using “mathpix” which has been great and isn’t too expensive if you don’t want to do too much).
The other thing that can cause problems is things like tables (eg if you were trying to ingest a lot of pdfs like financials of companies etc). Those can cause problems for both the ocr and the pure text extraction methods. I don’t have a current recommendation for that because I haven’t done it recently enough and the state of the art has moved a lot. It’s something to be aware of that will require special treatment though.
Producing "normal PDFs" that way actually requires specific LaTeX options to be enabled in my experience. Without that, PDF viewers have to perform all kinds of ugly hacks to even figure out what Unicode codepoint a given glyph is supposed to represent! PDFs are much more of a vector format than a layouting program than most people seem to realize.
> One thing I have consistently found useful is to look for “mojibake” (scrambled text caused by decoding in an unintended character encoding)
This is exactly the problem with PDFs: It's not regular mojibake (i.e. interpreting a string of text in the wrong charset), but rather some PDF processor's failed attempt at mapping glyphs back to codepoints without an explicit mapping table being present in the PDF, which is something that the creator actively has to do.
> “Image” Pdfs that have been produced via a scan so don’t actually contain a text transcript require actual OCR.
For the reason above and others, in my experience, OCR actually works significantly better than trying to "semantically parse" the PDF.
latexmk --lualatex -aux-directory=output -output-directory=output $<
> The cmap package provides character map tables, which make PDF files generated by pdfLATEX both searchable and copy-able in acrobat reader and other compliant PDF viewers.
(from https://ctan.org/pkg/cmap)
I tried various AI tools and the results ranged from absolute garbage to something-but-not-something-but-not-quite.
I went ahead and did a section of a huge PDF by hand, just to see if what I was asking for was even feasible. After more than several hours of painstaking work spread across multiple days, I got several chapters to look identical to the source PDF in some Markdown renderers. I had to use some HTML for the more complex tables. I converted some diagrams to Markdown and some to images linked to from the Markdown.
1. be made up.
2. have successfully nerd sniped HN
To what purpose I'm not sure.Testing an LLM bot?
If I can't connect MCP, there's really no selling point for me to use Gemini from my watch, car, smart speaker, etc. If I'm already bound to using my own front end, then I'm only evaluating Gemini as a model/API, at which point it has many competitors that may be cheaper or better fit for the task.
The Gemini apps suck.
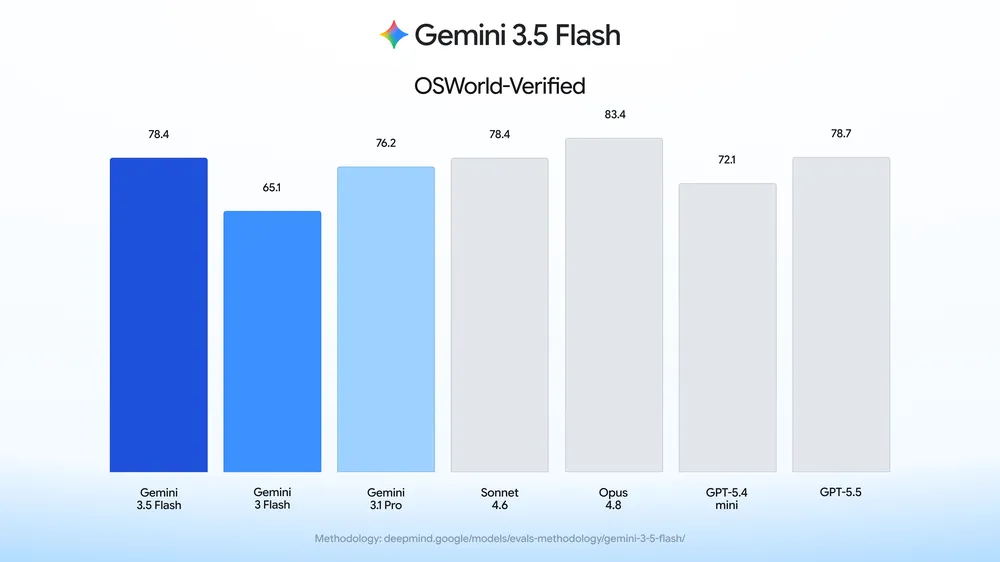
The methodology used:
https://deepmind.google/models/evals-methodology/gemini-3-5-...
Methodology: All Gemini scores are pass @1 except where otherwise noted. "Single attempt" settings allow no majority voting or parallel test-time compute. All of the results are all run with the Gemini API for the model-id gemini-3.5-flash with default sampling settings unless indicated otherwise below. To reduce variance, we average over multiple trials for smaller benchmarks.
All the results for non-Gemini models are sourced from providers' self reported numbers unless otherwise mentioned below. For Claude Opus 4.7 , Sonnet 4.6, and GPT-5.5 we default to reporting maximum thinking/reasoning settings available, but when reported results are not available we use best available reasoning results.
It’s something cheap enough you’d put out in front of your customers, and Opus is expensive enough you wouldn’t.
ChatGPT/Codex can do it, Claude can do it, why can't Gemini?
And no, I don't mean going through Antigravity, and personally I'm wary about LLMs having unsupervised access on my computer without explicit policy, so I really think Google is putting the cart before the horse here.
First headache was a lot of delays and 'service unavailable due to excessive load messages'. Second headache was a lot of frustration with the Continue plugin in my IDE. Gemini chat suggests I try the Antigravity app. I do so. IT's OK. Launch it on an agentic task, it gets part way through and stops, asking me to subscribe. Try getting it to use some of the Gemini credits I paid for a few days earlier. Turns out Antigravity is developed by a completely separate team within Google and they don't recognize or accommodate Gemini credits because they are trying to maintain budgetary independence so as to maintain operational autonomy Gemini. At least, that's the explanation Gemini (free tier) offered for why Antigravity (Free/subscription only) won't accept Gemini (prepaid/subscription) payments. What a time to be alive.
You won't be surprised to learn I switched to a competitor.
So we end up with companies acting in ways that don't help themselves or the consumer, but which have no reasonable mechanisms to correct any of this. So we end up with the two best entrants in the AI space being independent companies, all while we know that, in case of significant cuts, it's the companies that are attached to other huge, unrelated sources of revenue that will have easier time surviving. Gemini can mess up all they want as long as management still has Ads and youtube sitting there subsidizing them.
It has been close to unusable for anything serious. I did really like the ability of Gemini-pro models to ground their research using Google Search. This meant that they were often much more thorough and up to date in their recommendations and finding solutions that came to life after the models themselves were trained. But even using Gemini as a reviewer was a weak point in my harness because of the poor reliability of their service (529 or 503).
I’ve since paid for a search API(linkup, exa, and valyu) and hooked them up to Deepseekv4-pro. It has been doing a stellar job.
The key was to prompt them to systematically use search to validate their answers(not simply “use the tool”, but something like find possibilities using web search, then once you formulate a solution, validate it with this check list -
1. Is there a better way to do this in 2026?
2. Are the libraries and its docs you’re using up to date?
This seems to help very much based on experience.
no clue why google has dropped the ball this hard on IF.
I haven't tried it at that because for the short range tasks I gave it I found it around Sonnet level, but slower (because it takes more tries!) which makes it more expensive.
The old Flash models were great because they were fast.
3.5 Flash shows Google can work around the old "Good, Fast or Cheap: Pick any two" thing by picking none of them.
It is not better.
I guess if you're trying to get people to tokenmaxx it may look like a valid strategy, but ain't no way this will be delightful to users.
I think it's a symptom of just not understanding how LLMs should interface with the OS because we're still in their early days.
Eventually there'll be an iPhone moment for the ergonomics of LLM usage outside of coding
If you're a person trying to get their job done at a big company, but half your job is in 1-2 proprietary tools or is stuck behind an API you can't program against, computer use can allow you, a non-techie, to do your job more efficiently.
I think it's an awesome way to circumvent gate keepers and the IT department to let people accomplish their goals.
I run it in a VM using a headless wayland compositor, I'd never trust even fable with access to my real system.
Even then, an AI writing AHK scripts likely outperforms.
Example: adding copyright text box to bottom of every slide
F3::
pres := ComObjActive("PowerPoint.Application").ActivePresentation
Loop % pres.Slides.Count {
slide := pres.Slides.Item(A_Index)
box := slide.Shapes.AddTextbox(1, 100, 500, 500, 30)
box.TextFrame.TextRange.Text := "Copyright 2026. All Rights Reserved."
}
returnI have an agent doing price checks for me for an item on a certain website. Instead of blasting through a zillion tokens processing the DOM over and over, it loaded the page once and figured out how to download a json with the price.
How can I automate things behind an SSO wall? Even if it means I manually authorize it once and watch it do things on its own..
Claude computer use takes control of your whole computer inputs (mouse and keyboard) plus screenshots. You just log in, tell Claude you're logged in, and let it get to work. It'll use the browser you're logged in with.
The chrome extension is a little better because it only takes control of its own chrome tabs (again: you just log in.)
Or you can show an AI screenshots and ask it where to click.
Then you get a nice textual world that fits the LLM without having to rewrite every application to have a fullblown HTTP server.
If you can SAFELY do that it's a big moment. But to be clear safe is a massive problem. Until you see a big company start saying the AI can use your SSN, CC, bank password safely we aren't there yet.
The difference is that if openai gave you a product and it leaked a million peoples bank passwords it would destroy the entire company.
Again until a big tech product can bring that to a clean user experience we're not there yet. Even the most zealot openclaw users are not hooking their bank accounts into the AI yet. I'm sure they exist but I've not seen them.
Also every big tech computer use product actively screams for you not to give their agents secrets.
Seatbelts were regulated later. Your SSN and CC are regulated over a decade ago.
Meanwhile, the entire world economy:
Spreadsheets are fucking glorious, powerful, clever, amazing and delightful, in my view.
And yet having an agent able yo use a computer on your behalf is really useful.
Recently I gave a Nix OS vm to my hermes agent and it has been a good experience. I don't really care if destroy the machine I can just rollback to an earlier version, and for any meaningful data he creates for me I make sure he creates a repo, commit and pushes to my private Gitea instance.
It is, but there's no need for it to be viewing your screen, browsing websites and watching ads.
That stuff is for humans, not for LLMs.
I honestly cannot think of a single use case
Imagine you have a pretty exotic task you need to complete that involves converting a video file from one format to another.
You can use ChatGPT or something similar and the best you will get is either a script you can run on you machine that does what you need or he may decide to render a new video.
If you have something like OpenwebUI you could configure a MCP that converts videos and allow the model to use this MCP to do your task. This should work, but is quite a lot of work for something you'll ever do once.
But if the agent has it's own environment he can decide to install ffmpg, execute the transformation and serve you the file you want.
In reality there is no new capabilities with this approach, but things get a lot more comfortable.
It's the end game of AI. Have systems trained on doing EVERYTHING you do on a computer all day. Trained by you while doing the job.
Okay, fair, I haven't really paid attention to marketing.
> the LLM does not require computer use to see the GUI and
It can take screenshots without computer use, but it can't click around. I didn't have access to computer use until recently (I'm on an OS where Claude Code technically shouldn't run, I had to patch the binary), and when I got it working it made a big difference because of this.
I had the dubious pleasure of testing gemini of late and I kept running into refusals. How do I transfer a sim number from one provider to another? No. What should I consider when making backups on ntfs less prone to data loss and more bitrot resistant? No. Evaluate this piece of code? No.
I’m not sure if it’s cold feet from the mythos situation or what, but it reminds me of the dark days where you couldn’t use ai for much of anything. But then I go to chatgpt 5.5 and it does mostly everything I want outside of the usual cybersecurity boogeyman that you run into now and then.
What exactly are you saying it's refusing? Can you give a screenshot or example?
I guess it's economic wrt. token use, but it often either refused for absurd safety reasons, or other weird stuff like responding that an LLM like itself wasn't a suitable tool for the job, and very quickly gives up.
Claude is on the other end of the spectrum, which makes it more noticeable when switching between them.
It also could just be which way the wind was blowing for OP, the models are stochastic to some degree, but there is no shortage of complaints from (mostly euro) users getting stonewalled.
Ultimately I think that in 10 years time, this is what's gonna kill paid consumer LLMs, and boost the usage of Chinese LLMs self hosted at home an your own hardware that people will torrent via VPNs, as they will also be banned because of "disinformation and misinformation".
So the end winners will be the hardware companies that will sell AI chips to consumers after the datacenter bubble pops. Unless of course the EU will ban the sale of AI chips that don't have some limitations baked in on which models you're allowed to run (the state approved ones). Interesting times ahead. I think in 10-20 years time we'll look back at present day LLMs the way we look back at the open internet of the 90's-00's.
They are quite insane. I was asking it to list candidates metal parts I could buy at a hardware store to add weight to 3D prints: stuff like angle brackets etc.
I wanted to know, bang for bucks, and ease of insertion (at print time) / modelling in a 3D model.
Complete refusal as if I was a terrorist building a bomb.
Then there are the weird refusals that then are OK after all if you insist by asking it what's wrong about it:
"How should I cook eggs?"
"I'm sorry but I can't help you with that" (it formulates it differently but that's the idea)
"What, I'm just hungry, is explaining me how to cook eggs really against your rules?"
And then it answers "No of course not, here's how to do it:..."
Really strange stuff.
With Retriever AI, we construct custom accessibility trees to represent web pages and just switched over to using DeepSeek v4 Flash and its nearing 100x cost decrease.
We also had great success just reverse engineering the underlying APIs of websites and then writing code to hit them. This approach of using screenshots to take actions on a webpage to trigger the underlying network calls the website is making seems too naive.
The Codex computer use functionality actually uses OS level accessibility trees, so thats also possible without screenshots.
{kind=link}